Formulierung einer Fragestellung
Am Anfang einer empirischen Studie steht eine Theorie oder Fragestellung, die gleichzeitig einen roten Faden für Studienaufbau und Fragebogengestaltung vorgibt. Daraus werden Hypothesen abgeleitet. Daher ist schon beim Formulieren der Fragestellung besondere Sorgfalt geboten, die sich an folgendem Beispiel gut veranschaulichen lässt.
Beispiel: Formulieren einer Fragestellung „Lohnt es sich, viel Zeit auf die Vorbereitung auf Statistik-Klausuren zu verwenden?“ – das könnte eine typische Fragestellung im Umgang mit Statistik sein. Und obwohl vielleicht die Eine oder der Andere diese Frage klar für sich beantworten kann, ergeben sich bei näherer Betrachtung doch einige Schwierigkeiten. Zunächst ist schon die Wahl des Studienobjekts bzw. die Wahl der Fragestellung eine sehr subjektive Handlung. Und da gerade die Statistik versucht, möglichst objektiv Zusammenhänge aufzudecken, ist die Motivation dieser Wahl klar herauszustellen. Weitere Fragen sind dann zum Beispiel was sich "lohnt" und wieviel Zeit "viel Zeit" ist. Also ist es notwendig die Frage zu spezifizieren, und hier treffen wir schon auf die zweite subjektive Auswahl: „Führt mehr eingesetzte Zeit zu besseren Ergebnissen?“ könnte eine Spezifikation sein. Aber es gibt sicherlich noch zahlreiche weitere, die genauso richtig oder falsch sind. Zum Beispiel könnte man unter eingesetzter Zeit auch die Vor- und Nachbereitung von Vorlesungen verstehen, die Diskussion mit Kommilitonen, die Verarbeitung im Schlaf etc. Von dieser eher abstrakten Ebene ist es dann notwendig, diese Begriffe zu operationalisieren. D.h. es stellt sich die Frage danach, was „messbar“ bzw. „beobachtbar“ ist. Hier könnte die Wahl auf die Zeit der Klausurvorbereitung und die Vor- und Nachbereitung von Vorlesungen in Stunden fallen. Gleiches sollte für den Lernerfolg geschehen. Das ist ein sehr abstrakter Begriff, und es stellt sich generell die Frage, ob er gemessen werden kann. Ideen hierzu sind die erreichte Note, die erreichten Punktzahlen oder aber eine Selbsteinschätzung. Wir wollen nun jedoch versuchen die oben genannte Frage zu beantworten. Dazu stellen wir zum einen eine Hypothese auf, die ganz klar überprüft werden kann: „Je mehr Zeit aufgewendet wird, desto besser ist die Note“. Nun fehlt noch die Definition der Note: „Zusammenfassung von erreichten Punkten“. Aus dieser Vorarbeit lässt sich nun endlich eine Erwartung an die tatsächlichen Zahlen formulieren: „Die eingesetzte Lernzeit ist (positiv) korreliert mit der erreichten Anzahl von Punkten“.
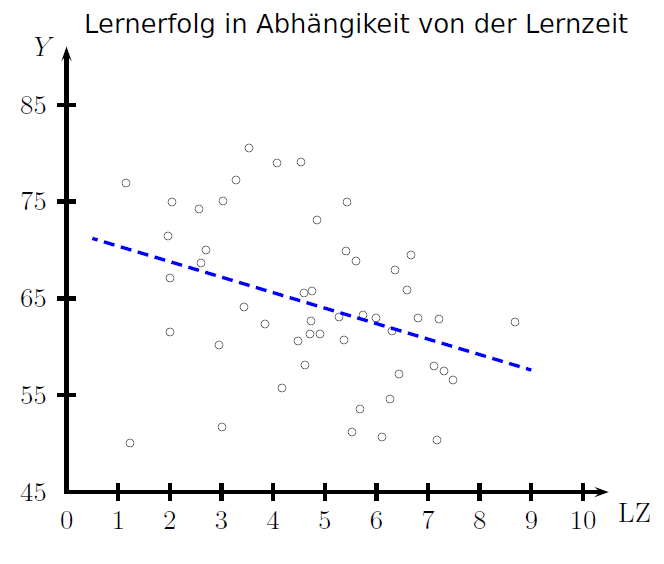
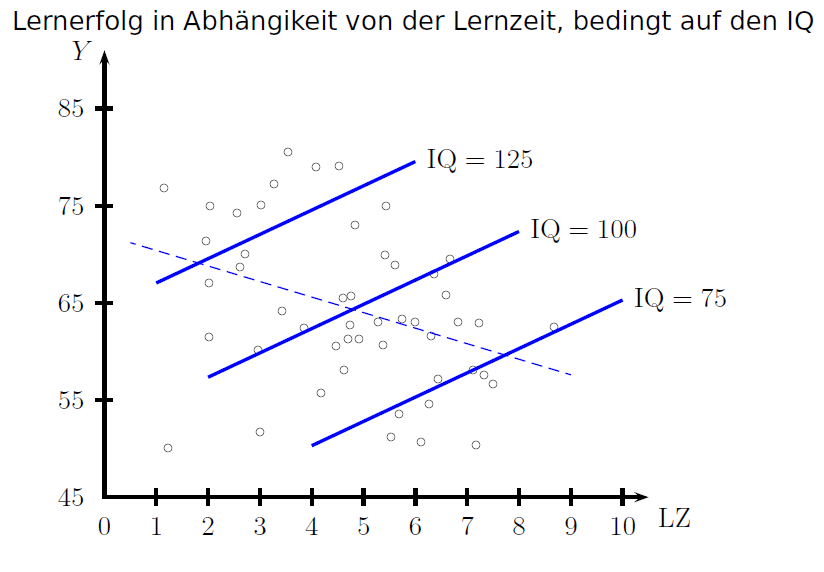
Die obige Abbildung weist, entgegen der Erwartung, auf einen negativen Zusammenhang hin, sodass man daraus schließen würde, dass je mehr Zeit aufgewendet wird, die Note schlechter ist., Dies sollte keinesfalls zum Abbruch des Forschungsvorhabens führen, sondern uns dazu bewegen einen Blick zurück in die Theorie zu werfen. Was gibt es denn für Faktoren, die den Lernerfolg beeinflussen? Da wären die aufgewendete Zeit, Veranlagung, Vorwissen, Intelligenz usw. All diese Faktoren haben einen positiven Effekt auf den Lernerfolg. In diesem Beispiel wird daher angenommen, dass das Verhältnis zwischen diesen Faktoren anderer Natur ist: Meist wenden Personen, die eine hohe Intelligenz besitzen, weniger Zeit fürs Lernen auf als diejenigen, die eine geringere Intelligenz besitzen. Dieses Verhältnis ist also negativ. Gleiches gilt für das Verhältnis der Veranlagung und aufgewendeter Zeit bzw. des Vorwissens und aufgewendeter Zeit. Es wäre also eine Möglichkeit, unsere bisherige Hypothese zu erweitern und eine der oben genannten Faktoren mit aufzunehmen: „Die eingesetzte Lernzeit ist, bedingt durch das Niveau des IQs, (positiv) korreliert mit der erreichten Anzahl von Punkten“. Die folgende Grafik zeigt uns, dass wir diesmal mit unserer Hypothese richtig liegen.
Dieses Beispiel zeigt, dass Rückschlüsse aus statistischen Analysen schnell in die Irre führen können, wenn sie nicht durch theoretische Vorüberlegungen motiviert sind oder durch theoretische Überlegungen hinterfragt werden. Hier würde die Interpretation der ersten Ergebnisse zur Aussage führen, dass Lernen sich nicht lohnt! Für etwaige Überprüfungen zusätzlicher theoretischer Überlegungen kann es sinnvoll sein, neben den eigentlichen Zielvariablen auch potienzielle Störvariablen in der Studie zu erheben. |
|---|
Es bleibt festzuhalten:
Eine empirische Arbeit sollte mit einer Forschungsfrage beginnen. Diese wird zuerst durch die Theorie beantwortet, und daraus werden wiederum Hypothesen abgeleitet. Meist sind mehrfache Revisionen der Hypothesen notwendig, bis daraus überprüfbare Hypothesen geworden sind. Es folgt die Operationalisierung („Messbar- bzw. Beobachtbarmachung“) von Zielgrößen und daraus die Wahl des geeigneten statistischen Verfahrens. Auch der Studienaufbau orientiert sich an den aufgestellten Hypothesen, ebenso die Erhebungsmethode und letztendlich die Erhebung selbst. Datenaufbereitung, Auswertung, die Darstellung und Interpretation der Ergebnisse ergeben sich dann zwangsläufig aus den Vorarbeiten.
Die vorgestellten Überlegungen sind unabdingbar für die erfolgreiche Planung und Durchführung einer Umfrage. Diese benötigen nämlich das zeitgleiche Durchdenken der Entwicklung der Fragestellung, der Erhebungsphase und der Analysephase. Auch wenn es schwer fällt, an die Datenauswertung zu denken, bevor überhaupt die erste Information erhoben wurde – genau dies sollte getan werden.
Beispiele: Fragen, die zur Überforderung führen können
Problem: Es stellt sich die Frage, ob mit den Randkategorien "vorsichtig" und "optimistisch" zwei Pole einer Dimension getroffen sind. Eindeutigere Gegensatzpaare sind "vorsichtig" und "unvorsichtig" bzw. "optimistisch" und "pessimistisch". Außerdem ist eine neutrale Kategorie sinnvoll, um Häufungen in der nichtssagenden „weiß nicht/ keine Angabe“ Kategorie zu vermeiden. Tatsächlich gibt es Fälle, in denen zunächst mit den Polen "optimistisch" und "pessimistisch" gearbeitet wurde. Im Pre-Test stellte sich heraus, dass die Skala nicht voll ausgeschöpft wird. Eine Erklärung dazu ist, dass der Begriff "pessimistisch" negativ konnotiert ist und sich daher nur Wenige als "Pessimist" benennen wollen. Um die Skala besser auszunutzen wurde der Pol "vorsichtig" als Alternative zu "pessimistisch" gewählt. 2. Unkonkrete Zeitangabe
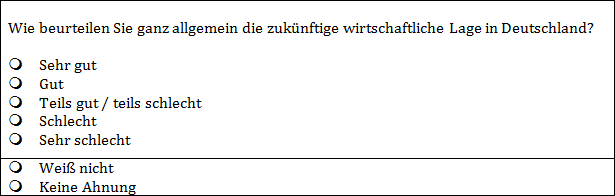
Problem: Der Ausdruck "zukünftig" ist unkonkret. Zukunft könnte sowohl als der nächste Monat, als auch als die kommenden 10 Jahre interpretiert werden, sodass sich die Einschätzungen schon auf Grund unterschiedlicher Interpretation unterscheiden könnten. 3. Ungenaues Intervall
Problem: Was bedeutet "regelmäßig": wöchentlich, monatlich, jährlich? Wie wäre z.B. ein jährlicher Kontakt im Kontext der Frage zu bewerten? |
|---|


Unklare Dimension
Die Beispielfrage ist angelehnt an Frage F065 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Unkonkrete Zeitangabe
Die Beispielfrage ist angelehnt an an Frage F001 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Ungenaues Intervall
Die Beispielfrage entspricht Frage F009 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
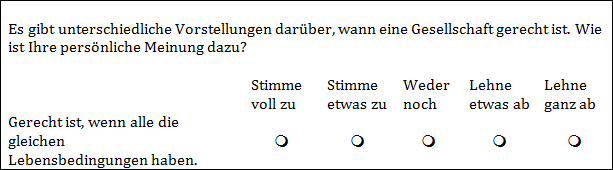
Beispiel: Likert-Skala Die Antwortmöglichkeiten sind ordinal skaliert, d.h. die Ablehnung oder Zustimmung ist absteigend oder aufsteigend angeordnet, ohne dass die Abstände interpretierbar sind.
|
|---|
Likert-Skala
Die Beispielfrage ist ein Teil der Frage F074 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Geschlossene Frage

Geschlossene Frage
Die Beispielfrage entspricht Frage F018 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Two-choice

Two-choice
Die Beispielfrage entspricht Frage F007C aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Multiple-choice mit Mehrfachantworten

Multiple-choice mit Mehrfachantworten
Die Beispielfrage angelehnt an Frage F007D aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Ratingfrage

Ratingfrage
Die Beispielfrage ist ein Teil von Frage F056 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288
Rankingfrage

Rankingfrage
Die Beispielfrage ist ein Teil von Frage F069 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288
Folgefrage: Beispiel mit den Mitarbeitern

Folgefrage: Beispiel mit den Mitarbeitern
Die Beispielfrage entstammt aus Internationale Sozialwissenschaftliche Umfrage 2013, Nationale Identität im Anschluss an GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. Fragebogendokumentation. GESISDatenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Beispiel: ALLBUS 2014, Variable Report
Die Kodierung der Variablen kann auch schon im Codebook um erste deskriptive Statistiken ergänzt werden.
|
|---|

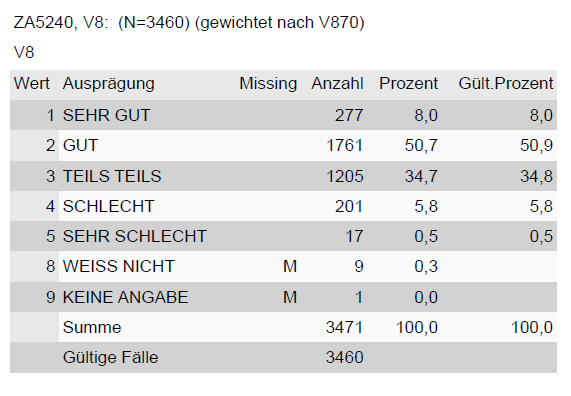
Beispiel: ALLBUS 2014, Variable Report
Beispiel aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014;Variable Report. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288.
Itembatterie
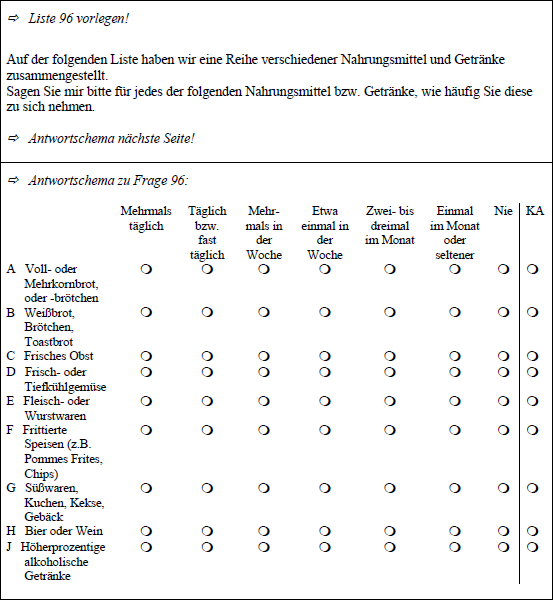
Itembatterie
Die Beispielfrage entspricht Frage F096 aus GESIS - Leibniz-Institut für Sozialwissenschaften (2015): Allgemeine Bevölkerungsumfrage der Sozialwissenschaften ALLBUS 2014. GESIS Datenarchiv, Köln. ZA5240 Datenfile Version 2.1.0, doi:10.4232/1.12288
Bildergalerie

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
|