Variablen und deren Zusammenhang
| abhängige Variable (\(y\)) | ordinal (Reihenfolge in Ausprägungen liegt vor) |
| unabhängige/n Variable/n (\(x\)) | beliebiges Skalenniveau (die Skalenniveaus der einzelnen \(x_1,...,x_P\) dürfen sich auch unterscheiden, liegt eine kategorische Variable vor, so muss eine Zerlegung in Dummy-Variablen stattfinden) |
Das Ziel der ordinalen Regression ist die Vorhersage von Wahrscheinlichkeiten für das Auftreten der einzelnen Kategorien in Abhängigkeit von Kovariablen.
Ein Beispiel für die Anwendung der ordinalen Regression stellen Likert-Skalen dar. Sie sind ein Spezialfall von Ordinalskalen, das heißt die Werte einer solchen Skala sind verschiedenartig und lassen sich einer eindeutigen Rangfolge zuordnen. Likert-Skalen werden genutzt, um persönliche Einstellungen (Zustimmung/Ablehnung) von Individuen zu messen, weshalb sie häufig als Antwortskalen in Umfragen verwendet werden. Typischerweise haben sie 3, 5, 7 oder 11 Werte.
Typische Likert-Skalen sind:
- überhaupt nicht (1) - wenig (2) - mittel (3) - stark (4) - sehr stark (5)
- trifft zu (1) - teils/teils (2) - trifft nicht zu (3)
Die erste Variable hat 5 Kategorien, die mit den Werten 1, 2, 3, 4 und 5 kodiert werden.
Es mag die Frage aufkommen, ob Likert-Skalen nicht auch mit linearen Regressionsmodellen analysiert werden können. Likert-Skalen stellen keine metrische abhängige Variable dar, daher sollte von der Nutzung von linearen Regressionsmodellen in der Regel abgesehen werden, es gibt jedoch einige Ausnahmen wie z.B. eine relativ große Anzahl an Kategorien (z.B. 11). Für weitere Informationen siehe hier.

Motivation über Schwellenwertmodelle
Ordinale Regressionsmodelle werden über Schwellenwertmodelle motiviert. Eine nicht beobachtbare Hintergrundvariable (auch latente Variable genannt) \(y^*\) wird angenommen, die metrisch ist. Das Modell lautet: \(y^*_i=x'_i\beta+\epsilon_i, \quad i=1,\dots,n\). Hierbei wird für die Verteilung der \(\epsilon_i\) eine Verteilungsfunktion \(F\) mit Erwartungswert 0 angenommen, die symmetrisch um die 0 verteilt ist. Häufig wird für \(F\) die Standardnormalverteilung angenommen. In diesem Spezialfall erhält man das Probit-Modell.
Anstatt den Zusammenhang zwischen der beobachtbaren ordinalen Variable und den Einflussvariablen zu schätzen, wird der Zusammenhang zwischen der latenten metrischen Variable und den Einflussvariablen geschätzt. Dabei stellen die beobachtbaren Kategorien (mit endlicher Anzahl an Kategorien (m + 1)) das Überschreiten der Schwelle der latenten metrischen Variablen dar:
$$y_i={\begin{cases}0\ ,&{\text{für}}&-\infty<y^*_i\leq\alpha_1\ ,\\1\ ,&{\text {für}}&\alpha_1<y^*_i\leq\alpha_2\ ,\\&\vdots\\m\ ,&{\text{für}}&\alpha_m<y^*_i\leq\infty\end{cases}}$$
\(\alpha_j \) (\( j = 1, 2, ..., m \)) stehen für geordnete Schwellenwerte, die neben den \( \beta \) auch geschätzt werden müssen. Weil der Wertebereich der latenten Variable nicht bekannt ist, nimmt man \( \alpha_0 = - \infty \) und \( \alpha_{m+1} = \infty \) an.
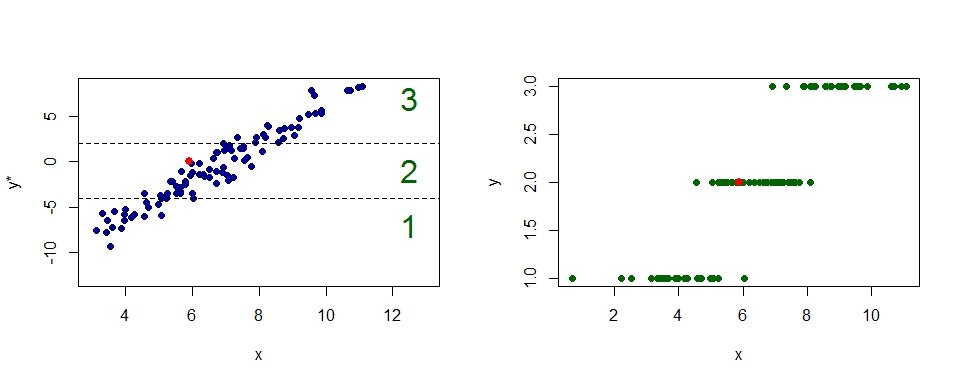
Die folgende Abbildung zeigt den Zusammenhang für eine Likert-Skala mit 3 Kategorien und einer Einflussvariablen \(x \). Der rote Punkt hat im ersten Bild die Koordinaten \( x = 5,9 \) und \(y^* = 0.05 \). Da \( y^*\) zwischen \(\alpha_1 = -4\) und \( \alpha_2 = 1 \) liegt, nimmt der \(y\) - Wert im zweiten Bild einen Wert von \( 2 \) an.
Bei der ordinalen Regression werden die Wahrscheinlichkeiten für das Auftreten von Kategorien \( j = 1, 2, ..., m \) durch erklärende Variablen \(x_1, x_2, ..., x_P\) mit Hilfe von bedingten kumulierten Wahrscheinlichkeiten \(P(y \leq j |x_i) = P(Y_i = 1 |x_i) + ... + P(Y_i = j |x_i)\) geschätzt, daher spricht man auch von kumulativen (Logit-/Probit-) Modellen.
Weil die Wahrscheinlichkeit für das Eintreten der höchsten Kategorie oder einer niedrigeren 100% beträgt ( \( P(Y_i \leq m |x_i) = 1 \) ), werden nur \(m - 1\) Kategorien modelliert, damit eine Überparametrisierung verhindert werden kann. Als Referenzkategorie wird im ordinalen Logitmodell entweder die kleinste oder größte Kategorie der Zielvariable ausgewählt.
Aus der Modellannahme über die latente Variable und das Schwellenwertkonzept ergibt sich das kumulative Modell mit Verteilungsfunktion \( F \)
\( P (Y_i = 1 | x_i) = F(\alpha_1 - x'_i \beta) \)
\(P (Y_i = j | x_i) = F(\alpha_j - x'_i \beta) - F(\alpha_{j - 1} - x'_i \beta),\) \( j = 2, ..., m - 1 \)
\(P (Y_i = m | x_i) = 1 - F(\alpha_{m - 1} - x'_i \beta) \)
Die Wahl von \( F\) bestimmt, ob ein Logit, Probit oder anderes Modell vorliegt.
Abbildung
Outputs in den verschiedenen Statistikprogrammen
Hier werden die Outputs aus den verschiedenen Statistikprogrammen vorgestellt. Die Outputs einer ordinalen Regression unterscheiden sich teils in den verschiedenen Statistikprogrammen. Sowohl sind die Werte unterschiedlich angeordet, als auch werden teils nicht die gleichen Werte ausgegeben. Einen hilfreichen Überblick über ausführlichere Code-Beispiele für die verschiedenen Statistikprogramme liefert folgende Website (Unterpunkt 'Ordinal Logistic Regression').
Im Folgenden werden die Werte 1-15, wenn vorhanden, an den Output der verschiedenen Statistikprogramme geschrieben, damit die Werte im Output gefunden werden können.
Output in R

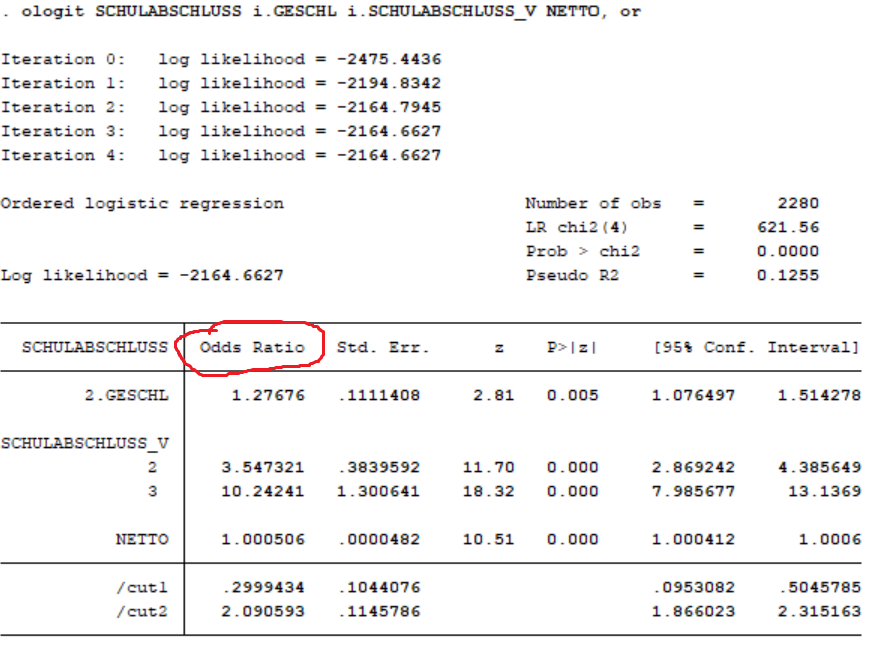
Output in Stata

Parameterinterpretation (Odds-Ratios)
Output in SPSS
Das kumulative Logit-Modell wird in SPSS über den Pfad Analysieren → Regression → Ordinal... durchgeführt. Für die Parameterinterpretation müssen die Odds Ratios händisch ausgerechnet werden (\(exp(\beta) \)).
Achtung: SPSS hat im Gegensatz zu den anderen Statistikprogrammen bei den Faktorvariablen GESCHL und SCHULABSCHLUSS_V eine andere Referenzkategorie gewählt. Entweder muss dies bei der Interpretation beachtet werden oder die Variablen müssen vorher transformiert werden. Hier wurden GESCHL (3 - GESCHL) und SCHULABSCHLUSS_V (4 - SCHULABSCHLUSS_V) transformiert, um die Ergebnisse analog interpretieren zu können.
Sie erhalten unter anderem diesen Output:


Output in SAS
Sie erhalten unter anderem diesen Output:



Anmerkung: SAS gibt statt den Schwellenwerten Intercepts aus, diese sind wie die Schwellenwerte nur mit negativem Vorzeichen.
