Versionen im Vergleich
Schlüssel
- Diese Zeile wurde hinzugefügt.
- Diese Zeile wurde entfernt.
- Formatierung wurde geändert.
Statistische Analyseverfahren, die mit den Begriffen Cluster- oder Paneldaten in Verbindung stehen, werden in verschiedenen Forschungsdisziplinen mit unterschiedlichen Synonymen bezeichnet. Gängige Bezeichnungen in der Psychologie, Medizin und empirischen Sozialforschung sind zum Beispiel Mehrebenenanalyse (multilevel modeling), Hierarchische lineare Modellierung (hierarchical linear models) und Analyse gemischter Modelle (mixed model analysis). In der Ökonometrie und den Sozialwissenschaften, vor allem in der Längsschnittforschung, wird vorrangig der Begriff der Paneldatenanalyse verwendet. In den meisten Fällen bezieht sich die Bezeichnung auf die Struktur der vorliegenden Daten.
| Tipp | ||
|---|---|---|
| ||
Mehrebenenanalyse
Panelanalyse
|
| Inhalt | ||||||
|---|---|---|---|---|---|---|
|
Datenstruktur
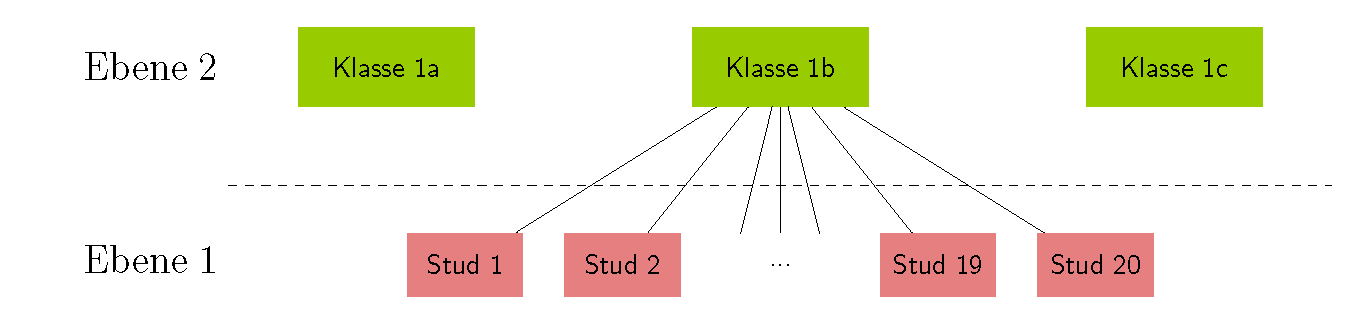
In einem Datensatz können Beobachtungseinheiten in mehreren Ebenen enthalten sein. Ein Beispiel mit zwei Ebenen aus der Bildungsforschung ist die Untersuchung des Lernerfolgs von Schülern (Ebene 1) aus verschiedenen Klassen (Ebene 2). Hierbei bilden die Beobachtungen der Schüler die erste Ebene und die Verschiedenen Klassen die zweite Ebene. Es können Charakteristika (Variablen) auf Schülerebene (z.B. Testergebnisse aus Leistungskontrollen, Geschlecht) und auf Klassenebene (z.B. Klassengröße, Eigenschaften des Klassenlehrers) im Datensatz enthalten sein. Die folgende Abbildung zeigt eine schematische Darstellung dieser Datenstruktur. Der Abbildung steht eine Datentabelle gegenüber, die verdeutlicht, wie die Daten organisiert sein müssen, um eine Mehrebenenanalyse durchführen zu können.
| Anker | ||||
|---|---|---|---|---|
|
Beispiel 1
| Office Excel | ||||
|---|---|---|---|---|
|
Diese Datenstruktur kann auf Beispiele aus anderen Forschungsdisziplinen übertragen werden: in der Paneldatenanalyse entsprechen die Individuen der Ebene 2 und die Zeitpunkte der Ebene 1; in klinischen Studien mit Patienten aus unterschiedlichen Kliniken entsprechen die Kliniken der zweiten Ebene und die Patienten der ersten Ebene. Das obige Beispiel aus der Bildungsforschung lässt sich auf mehr als zwei Ebenen erweitern. Werden die Schüler zum Beispiel über mehrerer Zeitpunkte beobachtet, kommt eine weitere Ebene hinzu.
Beispiel 2 Anker Beispiel 2 Beispiel 2
| Beispiel 2 | |
| Beispiel 2 |

| Office Excel | ||||
|---|---|---|---|---|
|
Analog zu dieser Erweiterung könnten in der Paneldatenanalyse die Individuen aus unterschiedlichen Regionen stammen. Die Regionen würden in diesem Fall Ebene 3, die Individuen Ebene 2 und die Zeitpunkte Ebene 1 entsprechen. Im Beispiel der Klinischen Studie könnten die Patienten über mehrere Zeitpunkte beobachtet werden, wobei die Kliniken dann Ebene 3, die Patienten Ebene 2 und die Zeitpunkte Ebene 1 entsprächen.
Die Datenstruktur bestimmt die Abhängigkeitsstruktur oder auch Clusterung in den Daten. Als Cluster werden allgemein Beobachtungen bezeichnet, die sich aufgrund von Gemeinsamkeiten ähneln. Im Beispiel wird die Abhängigkeit durch die Klassenzugehörigkeit bestimmt. Es ist zu erwarten, dass die Ergebnisse der Schüler innerhalb einer Klasse ähnlicher sind als die Ergebnisse im Vergleich zwischen den Klassen. Dies ist bedingt durch messbare klassenspezifische Faktoren, wie Klassengröße oder Geschlecht des Lehrers, aber auch durch nicht messbare Faktoren, wie Zusammengehörigkeitsgefühl oder Beziehung zum Lehrer. Werden die Schüler zusätzlich über verschiedene Zeitpunkte beobachtet, kommt eine zeitliche Abhängigkeit hinzu. Es ist zu erwarten, dass sich die Ergebnisse eines Schülers über die Zeit ähnlicher sind als die Ergebnisse unterschiedlicher Schüler. Dies ist Bedingt durch beobachtbare schülerspezifische Eigenschaften, wie Geschlecht oder sozioökonomische Kennzahlen des Elternhauses, aber auch nicht beobachtbaren Eigenschaften, wie Motivation für das Fach oder Begabung. Diese Abhängigkeit, die durch Zugehörigkeit in den verschieden Ebenen bedingt ist wird allgemein als Intraklassenkorrelation (geläufige Abkürzung ICC) bezeichnet.
Auswertungsmöglichkeiten
Hierarchisch organisierte Daten können auf verschiedene Weise analysiert werden. Analysemethoden unterscheiden sich hinsichtlich Ihrer Komplexität, wobei die Wahl der Methode an die Fragestellung gekoppelt sein sollte.
Für diesen Abschnitt soll folgendes gelten: die abhängige Variable liegt auf individualebene (Ebene 1) vor und wird mit \({y}\) gekennzeichnet; erklärende Variablen können auf individualebene, aber auch auf höheren Ebenen vorliegen, wobei erklärende Variablen der Eben 1 mit \({x}\) und erklärende Variablen der Ebene 2 mit \({z}\) gekennzeichnet werden. Erklärende Variablen aus höheren Ebenen geben Aufschluss über den übergeordenten Kontext aus dem die Individualbeobachtungen stammen und werden deshalb häufig als Kontextvariablen bezeichnet.
Aggregieren
In einem Datensatz mit zwei Ebenen werden die in Ebene 1 gemessen Variablen auf Ebene 2 zusammengefasst. Für die Daten aus Beispiel 1 hieße das, dass Mittelwerte über die Schüler innerhalb der einzelnen Klassen gebildet werden. Ist die Variation der Schüler innerhalb der Klassen gering und sind laut Fragestellung ausschließlich die Unterschiede ziwschen den Klassen von Interesse, kann das Aggregieren der Daten eine geeignete Methode sein. Ein Regressionsmodell für die Ergebnisse im Leistungstest auf Ebene 2 mit IQ und Klassengröße als erklärenden Variablen lautet
$$\bar{y}_{i} = \alpha_0+ \alpha_1 \bar{x}_{i} +\alpha_2 z_{i} + e_{i}$$
- \(\alpha_0\): Intercept
- \(\alpha_1\): Steigungsparameter; Effekt von \(x\) auf \(y\)
- \(\alpha_2\): Effekt der Kontextvariable \(z\) auf \(y\).
| Info |
|---|
Dieses Vorgehen entspricht in der Paneldatenanalyse der "between regression", in der die zeitlichen Mittelwerte der Individuen betrachtet werden. |
\(\bar{y}_{i}\) entspricht dem mittleren Testergebnis, \(\bar{x}_{i}\) dem mittleren IQ in Klasse \(i\) und \(z_i\) der Klassengöße von Klasse \(i\); \(e_{i}\) kennzeichnet den Fehlerterm des aggregierten Regressionsmodells. Dieses Vorgehen hat zur Folge, dass die Anzahl der verwendeten Beobachtungen auf die Anzahl der in Ebene 2 beobachteten Einheiten reduziert wird. Im Beispiel entspricht das der Anzahl der beobachteten Schulklassen.
Auswertung mit gepoolten Daten
Die hierarchische Datenstruktur wird ignoriert, und die Daten werden behandelt als wären sie unabhängig. Ein gepooltes Regressionsmodell für die Ergebnisse im Leistungstest auf Ebene 1 mit IQ und Klassengröße als erklärenden Variablen lautet
$$y_{ij} = \alpha_0+ \alpha_1 x_{ij} +\alpha_2 z_{i} + e_{ij}.$$
- \(\alpha_0\): Intercept
- \(\alpha_1\): Steigungsparameter; Effekt von \(x\) auf \(y\)
- \(\alpha_2\): Steigungsparameter; Effekt der Kontextvariable \(z\) auf \(y\)
Der Index \(ij\) kennzeichnet Individuum \(j\) in Klasse \(i\). Werden in ein Regressionsmodell Kontextvariablen \(z\) aufgenommen (die Aufnahme von Kontextvariablen ist optional), kann einen Teil der Abhängigkeit zwischen den Beobachtungen aufgefangen werden, da \(z\) eine Ursache für die Abhängigkeit sein kann. Es ist denkbar, dass größere Schulklassen tendenziell etwas schlechtere Ergebnisse aufweisen als kleinere Schulklassen. In diesem Fall wäre die Klassengröße eine Ursache für die Abhängigkeit in den Daten. Ein Teil der Abhängigkeit bleibt erhalten, wenn im Fehlerterm $e$ unbeobachtete klassenspezifische Eigenschaften enthalten sind, die Enfluss auf die Zielgröße \({y}\) haben. Diese unbeobachteten Einflussgrößen (auch als unbeobachtete Heterogenität bezeichnet) sorgen dafür, dass die Beobachtungen weiterhin abhängig sind. In einer OLS Regression, die Unabhängigkeit der Beobachtungen voraussetzt, könnte dieses Vorgehen eine fehlerhafte Inferenz zur Folge haben. Die Standardfehler würden tendenziell unterschätzt werden, was die Wahrscheinlichkeit erhöht Effekte fälschlicherweise als signifikant anzunehmen.
Mehrebenenanalyse
Modelle der Mehrebenenanalyse sind darauf ausgerichtet die Abhängigkeitstruktur durch geeignete Modellanpassungen zu berücksichtigen. Die unbeobachtete Heterogenität, die als Ursache für die Abhängigkeit der Beobachtungen angenommen wird, kann zum einen direkt als fester Effekt geschätzt werden. Zum Anderen kann die unbeobachtete Heterogenität als Teil des Fehlerterms aufgefasst werden (zufälliger Effekt). Hierbei wird die Varianz des Fehlerterms in verschiedene komponenten zerlegt, die Intraklassenkorrellation wird direkt geschätzt und bei der Schätzung des Intercepts und der Steigungsparameter des Regressionsmodells berücksichtigt.
Modell mit festen Effekten
Die unbeobachtete Heterogenität zwischen den Elementen der Ebene 2 wird direkt mit Hilfe von Dummievariablen berücksichtigt. Das bedeutet, dass spezifische Intercepts für jedes Element der Ebene 2 geschätzt werden. Damit können Abhängigkeiten, aufgrund unbeobachteter Heterogenität berücksichtigt werden. Das Regressionsmodell für die Ergebnisse im Leistungstest mit IQ und Klassengröße als erklärenden Variablen und klassenspezifischen Intercepts lautet
$$y_{ij} = \alpha_{0i}d_{i} + \alpha_1 x_{ij} + e_{ij}.$$
- \(\alpha_{0i}\): klassenspezifischer Intercept
- \(\alpha_1\): Effekt von \(x\) auf \(y\)
| Info |
|---|
In der Paneldatenanalyse entspricht dieses Vorgehen der fixed effects Regression mit einer within tranformation. |
Die Dummievariablen \(\d_i\) absorbieren die gesamte Heterogenität zwischen den Klassen, und eleminieren somit auch die Abhängigkeit der Beobachtungen innerhalb der Klassen. Die Fehlerterme können nun als unabhängig angenommen werden. Eine OLS Regression, die Unabhängigkeit der Beobachtungen voraussetzt, ist wieder zulässig. Dieser Modelltyp ist attraktiv aufgrung seiner Einfachheit, bringt jedoch auch Nachteile mit sich: Effizienzverlust, da für jedes Element der Ebene 2 ein Intercept geschätzt wird, was die Anzahl der Freiheitsgrade veringert; Kontextvariablen können nicht aufgenommen werden.
Modell mit zufälligen Effekten
Ein vollständiges lineares Zweiebenenmodell mit einer erklärenden Variable auf auf Individualebene \(X\) und einer auf Ebene 2 \(Z\) hat folgende formale Form:
$$Y_{ij} = \underbrace{\alpha_0+ \alpha_1 X_{ij} + \gamma_1 Z_j + \gamma_{11}Z_jX_{ij}}_{fester\,\, Teil} + \underbrace{u_{0j} + u_{1j} X_{ij}+ e_{ij}}_{zufälliger\,\, Teil}$$.
wobei der Index \(ij\) eine Ausprägung von Individuum \(i\) innerhalb einer Kategorie \(j\) aus Ebene 2 kennzeichnet. Mit den Daten aus Beispiel 1 entspräche \(Y\) den Ergebnissen aus dem Leistungstest, \(X\) dem IQ und \(Z\) der Klassengröße.Bei der Entwicklung eines Mehrebenenmodells für dieses Beispiel sollte inhaltlich überlegt werden welcher Teil des obigen Modells sinnvoll ist und aufgenommen werden soll. Folgende Tabelle zeigt die Bedeutung Parameters aus obiger Gleichung.
Frage: bei dem Beispeil bleiben, oder allgemein?
| Parameter | Beschreibung |
|---|---|
| \(\alpha_0\) | Intercept. Entspricht dem theoretischen Outcome, wenn alle erklärenden Variablen Null sind. Werden die erklärenden Variablen |
| \(\alpha_1\) | Effekt von \(X\) (IQ) auf \(Y\). Erklärt die Variation zwischen den Schülern |
| \(\gamma_1\) | Effekt der Kontextvariable \(Z_j\) (Klassengröße) auf \(Y\). Erklärt die Variation zwischen den Klassen |
| \(\gamma_{11}\) | Interaktionseffekt zwischen \(Z_j\) und \(X\) auf \(Y\). Wird in das Modell aufgenommen, der Effekt von IQ auf \(Y\) von der Klassengröße beeinflusst wird. |
| \(u_{0j}\) | Zufälliger Intercept. Beschreibt Unterschiede zwischen den Klassen. |
| \(u_{1j}\) |
An den Beschreibungen muss noch gearbeitet werden. Frage: Reicht eine allgemein einführung mit eine Intuition oder sollte es tiefer sein?
Modellwahl
So in der Art könnte dieser Teil ausssehen mit Verweisen auf Modellselektion in unserem Wiki
In order to conduct a multilevel model analysis, one would start with fixed coefficients (slopes and intercepts). One aspect would be allowed to vary at a time (that is, would be changed), and compared with the previous model in order to assess better model fit.There are three different questions that a researcher would ask in assessing a model. First, is it a good model? Second, is a more complex model better? Third, what contribution do individual predictors make to the model?
In order to assess models, different model fit statistics would be examined. One such statistic is the chi-square likelihood-ratio test, which assesses the difference between models. The likelihood-ratio test can be employed for model building in general, for examining what happens when effects in a model are allowed to vary, and when testing a dummy-coded categorical variable as a single effect.[2] However, the test can only be used when models are nested (meaning that a more complex model includes all of the effects of a simpler model). When testing non-nested models, comparisons between models can be made using the Akaike information criterion (AIC) or the Bayesian information criterion (BIC), among others See further Model selection.
Frage: Weitere Abschnitte, wenn ja, was sollte hier noch kommen