Datenstruktur
In einem Datensatz können Beobachtungseinheiten in
Datenstruktur
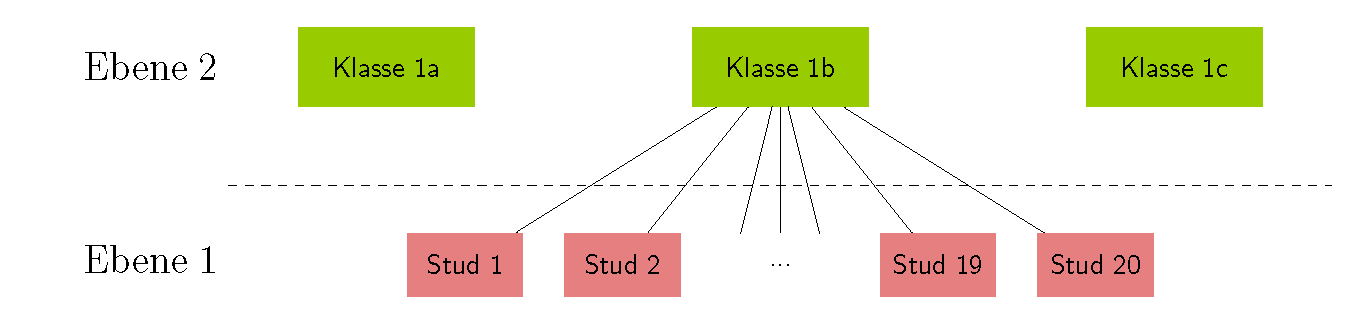
In einem Datensatz können Beobachtungseinheiten inmehreren Ebenen enthalten sein. Ein Beispiel mit zwei Ebenen aus der Bildungsforschung ist die Untersuchung des Lernerfolgs von Schülern (Ebene 1) aus verschiedenen Klassen (Ebene 2). Hierbei bilden die Beobachtungen der Schüler die erste Ebene und die
Verschiedenenverschiedenen Klassen die zweite Ebene. Es können Charakteristika (Variablen) auf Schülerebene (z. B. Testergebnisse aus Leistungskontrollen, Geschlecht) und auf Klassenebene (z.B. Klassengröße, Eigenschaften des Klassenlehrers) im Datensatz enthalten sein. Die
folgendeAbbildung Beispiel 1 zeigt eine schematische Darstellung dieser Datenstruktur. Der Abbildung steht eine Datentabelle gegenüber, die verdeutlicht, wie die Daten organisiert sein müssen, um eine Mehrebenenanalyse durchführen zu können.
Beispiel 1
| Office Excel | ||||
|---|---|---|---|---|
|

| Office Excel | ||||
|---|---|---|---|---|
|
Analog zu dieser Erweiterung könnten in der Paneldatenanalyse die Individuen aus unterschiedlichen Regionen stammen. Die Regionen würden in diesem Fall Ebene 3, die Individuen Ebene 2 und die Zeitpunkte Ebene 1 entsprechen. Im Beispiel der Klinischen Studie könnten die Patienten über mehrere Zeitpunkte beobachtet werden, wobei die Kliniken dann Ebene 3, die Patienten Ebene 2 und die Zeitpunkte Ebene 1 entsprächen.
Die Datenstruktur bestimmt die Abhängigkeitsstruktur oder auch Clusterung in den Daten. Als Cluster werden allgemein Beobachtungen bezeichnet, die sich aufgrund von Gemeinsamkeiten ähneln. Im Beispiel wird die Abhängigkeit durch die Klassenzugehörigkeit bestimmt. Es ist zu erwarten, dass die Ergebnisse der Schüler innerhalb einer Klasse ähnlicher sind als die Ergebnisse im Vergleich zwischen den Klassen. Dies ist bedingt durch messbare klassenspezifische Faktoren, wie Klassengröße oder Geschlecht des Lehrers, aber auch durch nicht messbare Faktoren, wie Zusammengehörigkeitsgefühl oder Beziehung zum Lehrer. Werden die Schüler zusätzlich über verschiedene Zeitpunkte beobachtet, kommt eine zeitliche Abhängigkeit hinzu. Es ist zu erwarten, dass sich die Ergebnisse eines Schülers über die Zeit ähnlicher sind als die Ergebnisse unterschiedlicher Schüler. Dies ist Bedingt durch beobachtbare schülerspezifische Eigenschaften, wie Geschlecht oder sozioökonomische Kennzahlen des Elternhauses, aber auch nicht beobachtbaren Eigenschaften, wie Motivation für das Fach oder Begabung. Diese Abhängigkeit, die durch Zugehörigkeit in den verschieden Ebenen bedingt ist wird allgemein als Intraklassenkorrelation (geläufige Abkürzung ICC) bezeichnet.
Beispiel 1
| Anker | ||||
|---|---|---|---|---|
|
| Office Excel | ||||
|---|---|---|---|---|
|
Beispiel 2 Anker Beispiel 2 Beispiel 2
| Beispiel 2 | |
| Beispiel 2 |
| Office Excel | ||||
|---|---|---|---|---|
|
$$\bar{y}_{i} = \alpha_0+ \alpha_1 \bar{x}_{i} +\alpha_2 z_{i} + e_{i}$$
$$e_{ij} \sim N(0,\sigma_e^2)$$
Modellparameter
$$\bar{y}_{i} = \alpha_0+ \alpha_1 \bar{x}_{i} +\alpha_2 z_{i} + e_{i}$$
- \(\alpha_0\): Intercept
- \(\alpha_1\): Steigungsparameter; Effekt von \(x\) auf \(y\)
- \(\alpha_2\): Effekt der Kontextvariable \(z\) auf \(y\).
| Info |
|---|
Dieses Vorgehen entspricht in der Paneldatenanalyse der "between regression", in der die zeitlichen Mittelwerte der Individuen betrachtet werden. |
\(\bar{y}_{i}\) entspricht dem mittleren Testergebnis, \(\bar{x}_{i}\) dem mittleren IQ in Klasse \(i\) und \(z_i\) der Klassengöße von Klasse \(i\); \(e_{i}\) kennzeichnet den Fehlerterm des aggregierten Regressionsmodells. Dieses Vorgehen hat zur Folge, dass die Anzahl der verwendeten Beobachtungen auf die Anzahl der in Ebene 2 beobachteten Einheiten reduziert wird. Im Beispiel entspricht das der Anzahl der beobachteten Schulklassen.
- \(\alpha_0\): InterceptRegressionskonstante
- \(\alpha_1\): Steigungsparameter; Effekt von \(x\) auf \(y\)
- \(\alpha_2\): Steigungsparameter; Effekt der Kontextvariable \(z\) auf \(y\)
- \(
$$y_{ij} = \alpha_{0i}+ \alpha_1 x_{ij} +\alpha_2 z_{i} + e_{ij}.$$
| Info |
|---|
In der Paneldatenanalyse entspricht dieses Vorgehen der fixed effects Regression mit einer within tranformation. |
- \sigma_e^2\): Varianz des Fehlerterms
$$y_{ij} = \alpha_0+ \alpha_1 x_{ij} +\alpha_2 z_{i} + e_{ij}.$$
$$e_{ij} \sim N(0,\sigma_e^2)$$
Modellparameter
- \(\alpha_0\): Regressionskonstante
- \(\alpha_1\): Effekt von \(x\) auf \(y\)
- \(\alpha_2\): Effekt der Kontextvariable \(z\) auf \(y\)
- \( \sigma_e^2\): Varianz des Fehlerterms
$$y_{ij} = \alpha_{0}+ \mu_i+ \alpha_1 x_{ij} + e_{ij}.$$
$$ e_{ij} \sim N(0,\sigma_e^2)$$
Modellparameter
- \(\alpha_{0}\): Regressionskonstante
- \(\mu_{i}\): klassenspezifische Verschiebung
- \(\alpha_1\): Effekt von \(x\) auf \(y\)
- \( \sigma_e^2\): Varianz des Fehlerterms
$$y_{ij} = \underbrace{\alpha_{0} + \alpha_1 x_{ij} +\alpha_2 z_{i}}_{feste\,\, Effekte} + \underbrace{u_{i}+ e_{ij}}_{Fehlerterm}$$
$$ e_{ij} \sim N(0,\sigma_e^2), \,\, u_{i} \sim N(0,\sigma_u^2)$$
Modellparameter
- \(\alpha_{0}\): Regressionskonstante
- \(\alpha_1\): Effekt von \(x\) auf \(y\)
- \(\alpha_2\): Effekt der Kontextvariable \(z\) auf \(y\)
- \( \sigma_e^2\): Varianz des individuellen Fehlerterms
- \( \sigma_u^2\): Varianz der gruppenspezifischen Konstante
$$y
Modell mit zufälligen Effekten
Ein vollständiges lineares Zweiebenenmodell mit einer erklärenden Variable auf auf Individualebene \(X\) und einer auf Ebene 2 \(Z\) hat folgende formale Form:
$$Y_{ij} =\underbrace{\alpha_{0} + \alpha_1
x_{ij} +\
alpha_2 z_{i} }_{
feste\,\,
Effekte} + \underbrace{
c_{
i}
x_{
ij}
+u_i + e_{ij}}_{
Fehlerterm}$$
$$ e_{ij} \sim N(0,\sigma_e^2), \,\, u_{i} \sim N(0,\sigma_u^2), \,\, c_{i} \sim N(0,\sigma_c^2)$$
$$Cov(u_i,c_i)=\rho$$
Modellparameter
wobei der Index \(ij\) eine Ausprägung von Individuum \(i\) innerhalb einer Kategorie \(j\) aus Ebene 2 kennzeichnet. Mit den Daten aus Beispiel 1 entspräche \(Y\) den Ergebnissen aus dem Leistungstest, \(X\) dem IQ und \(Z\) der Klassengröße.Bei der Entwicklung eines Mehrebenenmodells für dieses Beispiel sollte inhaltlich überlegt werden welcher Teil des obigen Modells sinnvoll ist und aufgenommen werden soll. Folgende Tabelle zeigt die Bedeutung Parameters aus obiger Gleichung.
Frage: bei dem Beispeil bleiben, oder allgemein?
- \(\alpha_{0}\)
- : Regressionskonstante
- \(\alpha_1\): Effekt von \(x\) auf \(y\)
- \(\alpha_
- 2\): Effekt der Kontextvariable \(z\)
- auf \(
- y\)
- \( \sigma_e^2\): Varianz des individuellen Fehlerterms
- \( \sigma_u^2\): Varianz der gruppenspezifischen Konstante
- \( \
- sigma_
- c^2\): Varianz des gruppenspezifischen Steigungsparameters