
Es macht Sinn, der Frage nach den Vorzügen von XML-Schemata die Frage nach dem Mehrwert allgemeiner Textkodierung voranzustellen. Kodierungen folgen einer Systematik, die dem Text ein Format verleiht. Auch wenn erprobte Standards bestehen, ist das Wie im Grunde jedem Kodierenden selbst überlassen. Das Format kann Text strukturieren, ihn mit einer Funktion versehen oder besondere Merkmale hervorheben. Es ermöglicht zudem eine Anreicherung des Texts mit zusätzlichen (Meta-)Informationen, z.B. Kommentaren, Angaben zum Autor des Codes, zum Entstehungszeitraum, etc.. Durch die systematische Struktur kodierter Texte lassen sich einzelne Textbausteine und Metainformationen präzise ansteuern und abrufen. Kodierungsstandards erlauben zudem, dass Texte/ Codes auch maschinell ausgelesen und "verstanden" werden können (z.B. HTML). Dies gilt nicht weniger in den Geisteswissenschaften. Je systematischer die Daten kodiert sind, desto effizienter lassen sich diese durchsuchen und gesuchte Informationen abrufen. Dass der direkte Zugriff auf die kodierten Daten hier dennoch eher die Ausnahme darstellt, liegt nicht zuletzt daran, dass eine Vielzahl von Tools Benutzeroberflächen bzw. Suchmasken bereitstellen, die einfachere Suchanfragen und Operationen ermöglichen. Diese Masken funktionieren nur vor dem Hintergrund einer kodierten Textgrundlage, minimieren jedoch im Sinne einer Vermeidung von Komplexität den direkten Kontakt zwischen dem Code und dem Nutzer.
...
Nehmen wir an, wir möchten die Suchmaske des LIP-Korpus nutzen, um Artikelwörter zu finden.
...
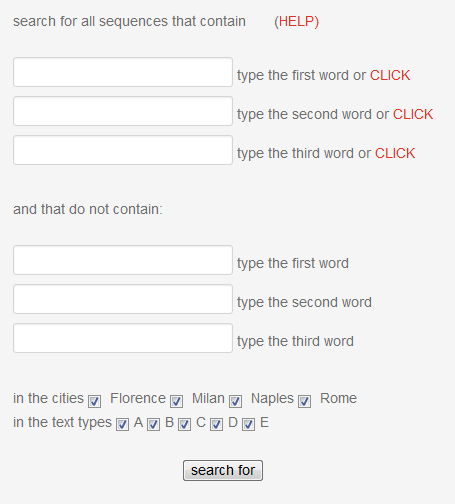 (Suchmaske des LIP-Korpus)
(Suchmaske des LIP-Korpus)
...
Die Oberfläche bietet uns hierfür mehrere mehr oder weniger geeignete Optionen. Zunächst lassen sich Artikelwörter über ihre Form definieren. Entweder wird hierzu jeder Artikel einzeln gesucht oder es werden Wildcards, sozusagen Platzhalter, verwendet, mit deren Hilfe sich ähnlich aussehende Artikel zusammenfassen lassen:
 (Sucht nach "il")
(Sucht nach "il")
 (Sucht nach "l" gefolgt von einem beliebigen Zeichen)
(Sucht nach "l" gefolgt von einem beliebigen Zeichen)
Abgesehen davon, dass diese Herangehensweise insbesondere bei allomorphen Strukturen einen Mehraufwand durch immer wieder neu zu startende Suchanfragen mit sich bringt, erschweren auch Homonyme die Suche. So sind die Formen lo und la (bzw. l_) nicht ausschließlich der Kategorie der Artikel zuzuordnen sondern auch der der Pronomen (z.B. lo - bestimmter Artikel und direktes Objektpronomen). Alternativ lässt sich auch nach der Wortart – auch in Kombination mit dem Lemma oder mit dem Lemma und dem Token – suchen.
...
Auch wenn somit für jede Form eine abrufbare Annotation vorliegt, kann die Benutzeroberfläche die Suchmöglichkeiten, die eine solche Annotation bietet, nicht komplett nutzen. Möchte man zum Beispiel ausschließlich die Artikel la und lo, d. h. l_, suchen, so kann dies nur ohne Angabe der Wortart erfolgen. Ein Input der Form .Ar.il.l_ erzeugt eine Fehlermeldung, während sowohl l_ als auch .Ar.il.lo zulässig sind. Wie noch in dem weiteren Verlauf dieses Manuals deutlich werden wird, sind Abfragen annotierter Textmerkmale in unmaskierten Textdaten durchaus möglich.
...
Das hier startende Manual dient der systematischen Einführung in die Datenkodierung mittels XML. Es schafft Grundlagenkenntnisse, die dabei helfen sollen, XML-Strukturen zu erkennen und zu verstehen. Der sich anschließende 2. Block befasst sich mit der Praxis der XML-Kodierung. Hier werden nicht nur unterschiedliche Typen der Textkodierung beleuchtet, sondern auch der TEI-Standard vertieft. Block 3 widmet sich dem Nutzen von XML für sprachwissenschaftsrelevante Anwendungen. Im Zusammenhang mit ausgewählten Tools rückt hier auch die Möglichkeit der Datenmodifikation in den Vordergrund. Zuletzt befasst sich ein abschließender Block mit der Auswertung von XML-kodiertem Text mithilfe von regulären Ausdrücken und xPath.
Allen Ausgewählten Blöcken werden Übungsaufgaben mit Lösungsvorschlägen beigefügt. Sie ermöglichen eine unmittelbare praktische Auseinandersetzung mit den XML-Strukturen und dienen der Routinisierung sinnvoller Operationen.
...