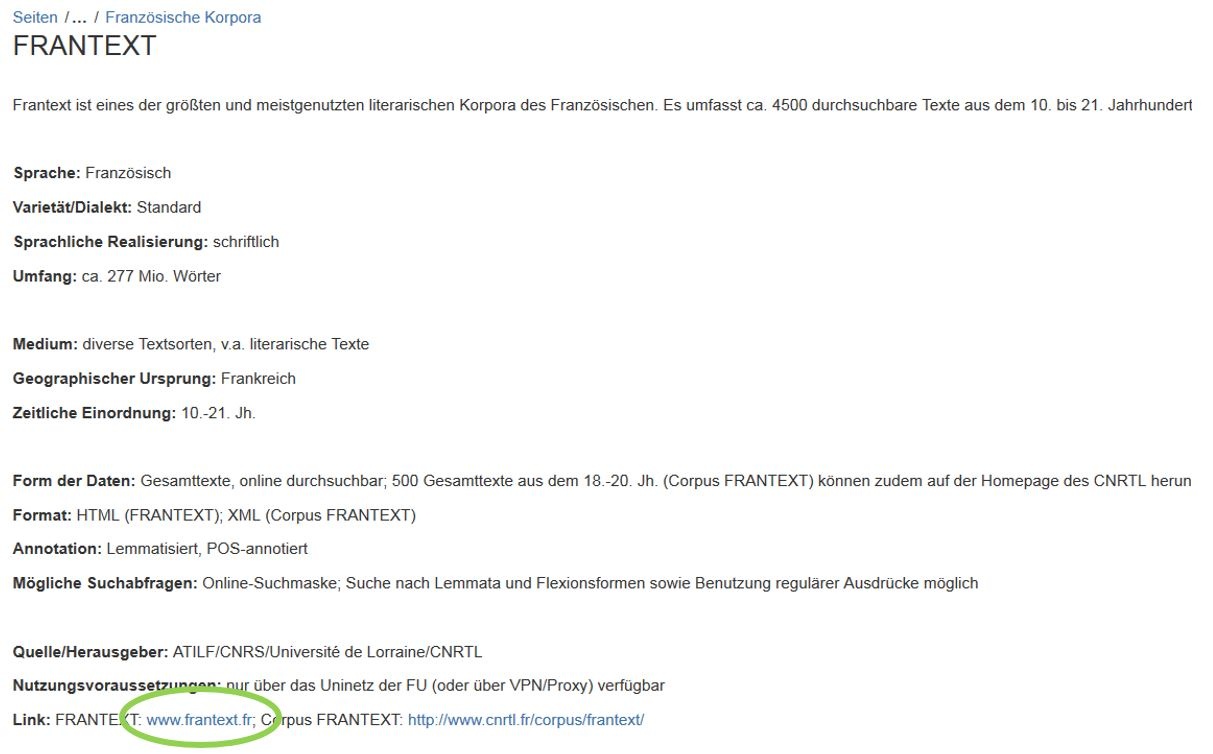
...
| Auszug |
|---|
Es lässt sich festhalten: Ein linguistisches Korpus ist eine Textsammlung, die
Ein Korpus muss quantitativ ausbalanciert sein. Das bedeutet nicht nur, dass die Textdaten einen gewissen Umfang aufweisen müssen, sondern auch, dass sie in ihrer Auswahl repräsentativ für den Referenzbereich sein müssen. Repräsentativität ist beispielsweise nicht gegeben, wenn man Aussagen über lexikalische Besonderheiten Südfrankreichs treffen will, jedoch ausschließlich Sprachdaten jüngerer Sprecher erhebt, da ihr Sprachgebrauch von dem älterer Sprecher abweichen kann und somit nicht mit dem generellen Usus Südfrankreichs gleichzusetzen ist. Liegt der notwendige Datenumfang nicht vor, so sollte der Untersuchungsgegenstand, um eine hohe Repräsentativität zu erhalten, möglichst differenziert gewählt werden (z.B. lexikalische Besonderheiten der in Marseille lebenden Gymnasiasten). Je stärker die Fragestellung diatopisch, diastratisch und diaphasisch präzisiert wird, desto repräsentativer kann die Datengrundlage gewählt werden. Auch sollte darauf geachtet werden, texttypologische Grenzen nicht zu überschreiten. In der Regel begrenzt sich die Datengrundlage auf einen einzigen Texttypus, z.B. Literatur, Zeitung, Gesetzestexte, Blogs, transkribierte Sprachaufnahmen, etc.. Im Hinblick auf das Datenformat muss vermerkt werden, dass Textdaten nicht einfach als Fließtext vorliegen, sondern in irgendeiner Weise aufbereitet wurden:
Ein Kodierungsstandard macht es möglich, große Datenmengen automatisiert und schnell zu durchsuchen und zu analysieren, da er bewirkt, dass sprachliche Merkmale computerlesbar und dadurch zählbar gemacht werden. Sind die Textdaten mit linguistisch orientierten Annotationen oder Metadaten versehen, so können Sprachregister, Varietäten, Sprachwandel, Sprachkontakt usw. bei der Analyse der Frequenzen charakteristischer Merkmale berücksichtigt werden. Auf diese Weise wird dem Zusammenhang zwischen außersprachlichen Faktoren (Alter, Herkunft, Bildung…) und sprachlichen Phänomenen (Soziolinguistik) die notwendige Aufmerksamkeit zuteil. Korpora im TdR-WikiDie Korpora lassen sich im TdR-Wiki über den Menüpunkt "Korpora und Textdatenbanken" annavigieren. Mit Ausnahme der offline verfügbaren Korpora, die eine eigenständige Kategorie bilden, sind sie nach Sprachen kategorisiert. Seiten zu den einzelnen Korpora enthalten zum einen eine Kurzdarstellung ihrer Zusammensetzung, zum anderen einen Link, der jeweils auf die entsprechende Wiki-externe Korpusseite führt. Korpora können zugansbeschränkt und somit nur über eine Universitäts-IP aufrufbar sein. Private Rechner können diese Beschränkung entweder durch das eduroam-Netz oder mithilfe eines VPN-Tunnels gegebenenfalls umgehen. |
| Anker | ||||
|---|---|---|---|---|
|
| Auszug |
|---|
Ein Beispiel für die Arbeit an TextdatenAnhand von FRANTEXT soll hier exemplarisch die Frage nach der diachronischen Unterschiede in der Verwendung von fin de semaine vs. week-end beantwortet werden. Zugang zum Korpus erhält man mithilfe des VPN-Tunnels über den Frantext-Eintrag im TdR-Wiki:
Die "Recherche simple" ermöglicht es, nach exakten Wortfolgen zu suchen:
Im Sinne einer Darstellung diachronischer Abweichungen sollte im nächsten Schritt die chronologische Ebene als Grundlage der Sortierung vermerkt werden:
Die Suche nach fin de semaine zeigt unter anderem folgende Ergebnisse an:
Die chronologische Sortierung macht es möglich, die Verwendung von fin de semaine bis auf das Jahr 1654 zurückzuführen. Dies bedeutet nicht, dass das Syntagma dort zum ersten mal verwendet wurde, sondern lediglich, dass der erste Text in FRANTEXT, der fin de semaine enthält, sich auf dieses Jahr datieren lässt. Für die jüngste Verwendung in FRANTEXT lässt sich das Jahr 2009 feststellen:
Eine entsprechende Suchanfrage lässt sich auch für week-end durchführen:
Die erste und die jüngste Verwendung in Frantext lassen sich respektive auf 1923 und 2012 datieren.
Aus diesen Ergebnissen ergibt sich folgendes Bild. fin de semaine bildet die ältere, week-end die wesentlich jüngere Form. Beide Formen koexistieren bis midestens 2009 in der französischen Literatur, bis sich week-end schließlich durchsetzt. Dieses Resultat sollte jedoch nicht generalisiert werden, da seine Aussagekraft eher begrenzt ist. So werden regionale und stilistische Besonderheiten (Québécois, Anglizismen…) sowie jeglicher nicht-literarischer Sprachgebrauch ausgeklammert. Es lässt regionale und stilistische Besonderheiten sowie jeglichen nicht-literarischen Sprachgebrauch außen vor, da sich jedes Korpus auf seinen individuellen Referenzbereich beschränkt. Es sei zu dem zu erwähnen, dass es sich bei FRANTEXT strikt betrachtet um gar kein Korpus, sondern lediglich um eine Textdatenbank handelt. Der Unterschied liegt darin, dass FRANTEXT nicht quantitativ ausbalanciert ist, weder im Hinblick auf das texttypologische Kriterium (d.h. er eben nicht so zusammengesetzt ist, dass er z.B. 10.000 Tokens aus der Kategorie "traité", 10.000 aus der Kategorie "essai", ... enthält) noch hinsichtlich einzelner Autoren (so gehen beispielsweise 5 der 17 Texte aus dem Zeitraum 1150-1200 auf Chrétien de Troyes zurück, was bedeutet, dass seine individuellen sprachlichen Vorlieben bei der Analyse sehr stark ins Gewicht fallen werden). Um die Ressource als Korpus nutzen zu können, muss die Datengrundlage deshalb zunächst quantitativ zugeschnitten werden. |







...