Varianzanalyse/ANOVA
Die Varianzanalyse oder ANOVA (von analysis of variance) ist ein Verfahren, welches auf Gruppenunterschiede testet. Der Name Varianzanalyse kommt daher, dass versucht wird die Gesamtvarianz der abhängigen, metrischen Variable zu zerlegen. Dabei wird ein (möglichst großer) Teil der Varianz durch die unabhängigen Faktoren erklärt (Varianz zwischen den Gruppen) während die restliche, nicht erklärbare Varianz als Zufallsprozess aufgefasst wird (Varianz innerhalb der Gruppen). In ihrer einfachsten Form, der einfaktoriellen Varianzanalyse, ist sie als Verallgemeinerung des zwei-Stichproben t-Tests auf Mehr-Gruppen-Vergleiche darstellbar. Natürlich könnte man für alle mögliche Gruppenvergleiche auch paarweise t-Tests durchführen (führt zur Alphafehler-Kummulierung, häufig auch \(\alpha\)-Fehler-Inflation, siehe Artikel über multiples Testen), die Varianzanalyse bietet jedoch mehrere Vorteile. So kann getestet werden, ob ein Faktor als ganzes einen Erklärungsgehalt besitzt und es existieren effiziente Testverfahren für multiple Vergleiche (siehe Artikel über multiples Testen). Außerdem bietet sie eine etwas effizientere Schätzung, wenn man davon ausgeht, dass die Varianzen in den Gruppen gleich sind (Varianzhomogenität), da so nur ein Varianzparameter geschätzt werden muss.
Einfaktorielle Varianzanalyse
Zunächst wird der einfachste Fall, die einfaktorielle Varianzanalyse, behandelt. Getestet werden soll, ob es Mittelwertsunterschiede zwischen mindestens 3 unabhängigen Stichproben gibt, dabei entspricht der Gesamt-Stichprobenumfang der Summe der Teil-Stichprobenumfänge. Die abhängige Variable muss dabei metrisch skaliert sein (z.B. Körpergröße). Die kategoriale Variable mit \(I\) Kategorien (Ausprägungen) die die Gesamt-Stichprobe in \(I\) unabhängige Teil-Stichproben teilt nennt man Faktor. Die einzelnen Kategorien (Ausprägungen) eines Faktors werden Faktorstufen genannt. Wenn nur der Einfluss von einem Faktor gemessen werden soll, spricht man von der einfaktoriellen Varianzanalyse. Die zu testende Nullhypothese lautet
$$H_0: \mu_1=\mu_2=... =\mu_I$$.
In Worten: Es gibt keine Mittelwertsunterschiede zwischen den \(I\) Faktorstufen.
Die Alternativhypothese lautet:
$$H_1: \exists i,j:\ \mu_i \neq \mu_j $$
In Worten: Es gibt zwischen mindestens zwei Mittelwerten einen signifikanten Unterschied.
Wie bei jeder statistischen Auswertung empfiehlt sich zunächst eine deskriptive Analyse um sich einen Überblick über die Daten zu veschaffen. Hierfür eignet sich, die Ausgabe der Mittelwerte und Standardabweichungen in den einzelnen Gruppen. Um weitere Einblicke über die Verteilung der Daten in den einzelnen Gruppen zu erlangen eignen sich graphische Methoden, wie Boxplots und Balkendiagramme der Mittelwerte mit Standardfehlern oder Konfidenzintervallen (bzgl. des Mittelwerts).
Neben der einfachen einfaktoriellen Varianzanalyse existieren noch eine Vielzahl von Erweiterungen und Generalisierungen, auf welche später noch eingegangen wird.
Annahmen:
Für die Gültigkeit der statistischen Tests wird von 3 zentralen Annahmen ausgegangen:
- Normalverteilte Residuen: Die Fehlerterme sind normalverteilt, d.h. \(\epsilon \sim N(0,\sigma^2)\).
- Varianzhomogenität: Die Fehlertermvarianz (\sigma) wird über alle Gruppen gleich angenommen (Homoskedastizitätsannahme).
- Die Stichproben sind unabhängig.
Die erste Annahme lässt sich grafisch über einen QQ-Plot überprüfen. Ein häufiger Fehler der gemacht wird, ist die Werte der abhängigen Variablen selber zu verwenden (\(y_i\)), statt der Residuen (\(\epsilon_i\)). Alternativ kann man die Residuen auch mit einem Test auf Normalverteilung (z.B. Kolmogorov-Smirnov-Test oder Shapiro-Wilk) überprüfen, jedoch ist dies nur begrenzt sinnvoll (siehe folgende Diskussion: http://stats.stackexchange.com/questions/2492/is-normality-testing-essentially-useless). Solange es zu keinen gravierenden Abweichungen von der Normalverteilung kommt ist diese Annahme insbesondere bei großen Fallzahlen aufgrund des zentralen Grenzwertsatzes bei kleineren Abweichungen vom Idealfall tolerabel.
Die zweite Annahme kann man mit Hilfe des Levene-Test überprüfen (wobei dieser eine relativ geringe Power besitzt). Auch hier gilt, dass die Varianzanalyse relativ robust gegenüber leichten bis mittleren Verletzungen dieser Annahme ist, wie viele Simulationen gezeigt haben.
Falls die obigen Annahmen erheblich verletzt sind, empfiehlt es sich zunächst eine Transformation der abhängigen Variablen vorzunehmen. Sinnvoll sind insbesondere die Logarithmus-Transformation, da viele Variablen wie z.B. das Einkommen eher auf einer multiplikativen Skala statt einer additiven Skala Sinn ergeben. Weitere Transformationen sind die Wurzeltransformation oder die Box-Cox-Transformation. Wenn dies immer noch nicht zum Erfolg führt, gibt es nichtparametrische bzw. robuste Alternativen (siehe unten).
Grundlegende Testidee:
Gegeben sei \(x_{ij}\) die j-te Beobachtung der i-ten unabhängigen Stichprobe und \(\overline{x}\) der Mittelwert der Gesamt-Stichprobe, sowie \(\overline{x}_{i}\) der Mittelwert der i-te Gruppe (Teilstichprobe). Daraus folgt:
$$x_{ij}=\overline{x}+\underbrace{\overline{x}_{i}-\overline{x}}_{Abweichung\text{ } Gruppenmittel \text{ } vom \text{ }Gesamtmittel} + \underbrace{(x_{ij}-\overline{x_{i}})}_{Abweichung\text{ } Beobachtung \text{ }vom\text{ } Gruppenmittel}.$$
Unter der \(H_{0}\), wird die Abweichung der Gruppenmittel zum Gesamtmittel klein sein im Vergleich zur Abweichung der Beobachtung zum Gruppenmittel. Eine hohe Abweichung der Gruppenmittel zum Gesamtmittel im Vergleich zur Abweichung der Beobachtung zum Gruppenmittel spricht dagegen für die \(H_{1}\).
Formal folgt daraus, die folgende Teststatistik:
$$F_{0,\alpha}:=\frac{\frac{1}{I-1}SSA}{\frac{1}{n-1}SSE}=\frac{\frac{1}{I-1}J\sum_{i=1}^{J}(\overline{x}_{i}-\overline{x})^{2}}{\frac{1}{n-1}\sum_{i=1}^{I}\sum_{j}^{J}(x_{ij}-\overline{x}_{i})^2}$$
- SSA:= Sum of Squared erors of All treatment, (sample) means vs. grand mean (Quadratische Abweichung der Mittelwerte vom Gesamtmittelwert der Gruppen).
- SSE:= Sum of Squared Errors of all observation vs. respective sample means (gesamte Abweichung von den Mittelwerten in den Gruppen).
- SST:= Sum of Squared errors Total for all observations vs. grand mean = SSA+SSE
Je weiter die Mittelwerterte der einzelnen Faktorstufen vom Gesamtmittelwert abweichen, desto größer wird der Wert für SSA, im Vergleich zum Wert für SSE. Bei Gültigkeit der \(H_{0}\) sollte der Quotient \(\frac{SSA}{SSE}\) nahe bei Null liegen. Je größer SSA wird -und somit auch \(\frac{SSA}{SSE}\)- desto unwahrscheinlicher ist die Gültigkeit der \(H_{0}\). Bei zu großen Werten von F wird \(H_{0}\) zu gunsten der \(H_{1}\) verworfen.
Post-Hoc-Tests:
Wird die \(H_{0}\) der einfaktoriellen Varianzanalyse verworfen bedeutet dies, dass es einen Mittelwertsunterschied zwischen mindestens zwei Gruppen gibt. Da es sich bei dem F-Test der Varianzanalyse um einen globalen Test (Omnibustest) handelt haben wir keine Information darüber, zwischen welchen zwei Gruppen, der \(I\) Gruppen, ein Mittelwertsunterschied vorliegt. Um zu überprüfen welche zwei Gruppenmittelwerte der \(I\) Gruppen sich signifikant voneinander unterscheiden, werden sogenannte Post-Hoc-Tests verwendet. Ein naives Vorgehen wäre die paarweise Überprüfung mit Hilfe von t-Tests, da es hierbei aber zur bereits erwähnten Alphafehler-Kumulierung kommt, gibt es speziel entwickelte Testverfahren. Eine sehr gute Übersicht über die gängigen Post-Hoc-Tests findet man unter: https://de.wikipedia.org/wiki/Post-hoc-Test.
Beispiel:
Die einfaktorielle Varianzanalyse wird jetzt mit Hilfe eines Beispiels genauer erläutert. Es soll anhand einer Umfrage unter Studenten der wirtschaftswissenschaftlichen Fakultät der FU-Berlin überprüft werden, ob es signifikante Körpergrößenunterschiede zwischen Studenten aus Berlin, aus einem anderen Bundesland und dem Auslang gibt. Die abhängige metrischen Variable ist hierbei die Körpergröße und die Herkunft (mit den drei Ausprägungen, Faktorstufen) fungiert als Faktorvariable. In diesem Beispiel wird davon ausgegangen, dass alle Annahmen der ANOVA erfüllt sind.
Nach Durchführung der einfaktoriellen Varianzanalyse mit SPSS erhalten wir folgende Ausgabe:
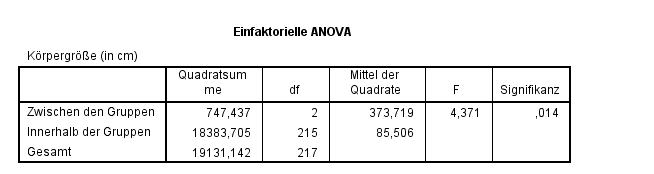
In der Ausgabe finden wir Informationen zu den Quadratsummen zwischen und innerhalb der Gruppen. Wie aus der Berschreibung der grundlegenden Testidee ersichtlich wurde, sprechen hohe Abweichungen zwischen den Gruppen im Verhältnis zu kleinen Abweichungen innerhalb der Gruppen für die \(H_{1}\). Die Berechnung des Quotienten \(373.719/85.506\) ergibt den Wert der Teststatistik \(F=4.371\). Um die Testentscheidung zu treffen gibt uns SPSS außerdem den p-Wert unter dem Namen "Signifikanz" aus. Da der p-Wert mit \(0.014 < 5%\) ist, lehnen wir die \(H_{0}\) ab. Inhaltlich bedeuted dies, dass es zu einem Signifikanzniveau von 5% einen signifikanten Körpergrößenunterschied (Mittelwertsunterschied) zwischen den Studierenden mit unterschiedlicher Herkunft gibt. Um nun herauszufinden zwischen welchen Mittelwertspaaren es signifikante Unterschiede gibt wird ein Post-Hoc-Test (der Least significant difference test (LSD)) verwendet.
Nach Durchführung des Post-Hoc-Tests erhalten wir folgende Ausgabe:
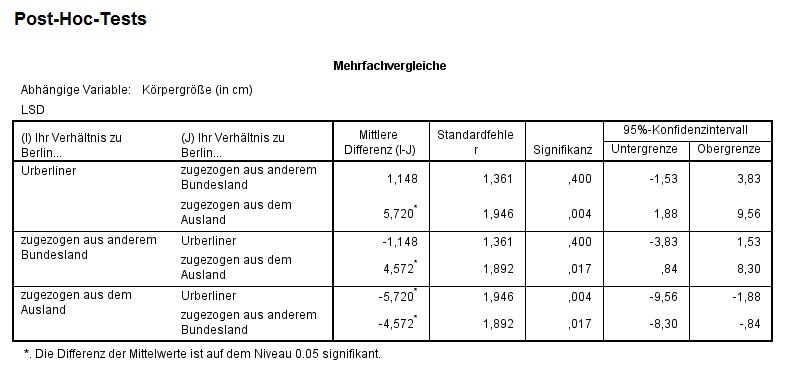
Wie aus der Abbildung ersichtlich wird, werden alle Gruppen paarweise miteinander verglichen (Urberliner mit zugezogen aus anderem Bundesland, Urberliner mit zugezogen aus dem Ausland, usw.). Der Output zeigt die Differenz zwischen den Mittelwerten der Gruppen, den Standardfehler, den p-Wert (unter Signifikanz) und das 95%-Konfidenzintervall. Inhaltlich kann gesagt werden, dass es zu einem signifikanzniveau von 5% signifikante Größenunterschiede zwischen Urberlinern und Studenten die zugezogen aus dem Ausland sind gibt (\(p-Wert=0.004<5%\)), sowie zwischen Studenten die zugezogen aus einem anderen Bundesland und zugezogen aus dem Ausland sind gibt. Die Testentscheidung kann natürlich auch mit Hilfe des 95%-Konfidenzintervalls getroffen werden. Beim Blick auf das Konfidenzintervall für die Mittlere Differenz zwischen Urberlinern und Studenten die zuegzogen sind aus dem Ausland fällt auf, dass dieses die 0 nicht beinhaltet \([ 1.88;9.56 ] \). Die inhaltliche Interpretation entspricht der Interpretation des Testergebnisses.
Kruskal-Wallis-Test als nichtparametrische Alternative
Wenn die Normalverteilungsannahme der einfaktoriellen ANOVA nicht erfüllt ist, kann auf den Kruskal-Wallis Test als nichtparametrische Alternative zurückgegriffen werden. Der Kruskal-Wallis-Test kann als Verallgemeinerung des, für den 2 Stichprobenfall verwendeten Mann-Whitney-U-Tests verstanden werden. Betrachtet werden, wie beim Mann-Whitney-U-Test, nicht die konkreten Realisierungen \(x_{ij}\), sondern die entsprechenden Ränge \(R_{ij}\). Die zu testende Nullhypothese lautet: \(H_{0}:\) Die \(I\) Stichproben entstammen der gleichen Grundgesamtheit.
Grundlegende Testidee:
Um die Testentscheidung zu treffen, sprich die \(H_{0}\) abzulehnen oder beizubehalten, wird die Teststatistik \(H\) berechet. Dafür werden alle Stichproben vereinigt und allen \(n\) Realisierungen \(x_{ij}\), Ränge \(R_{ij}\) zugewiesen. Anschließend folgt die Berechnung der Rangsummen \(R_{i}\) für die einzelnen Gruppen. Wenn keine Bindungen vorliegen, also keine Realisierungen doppelt vorkommen, ergibt sich die folgende Teststatistik:
$$H= \tfrac{12}{n(n+1)}\sum_h\tfrac{S_i^2}{n_i}-3(n+1)$$
Wenn Bindungen vorliegen muss die folgende Teststatistik verwendet werden:
$$H= \frac{\tfrac{12}{n(n+1)}\sum_h\tfrac{S_h^2}{n_h}-3(n+1)}{1-\tfrac{1}{(n^3-n)} \sum t_{r(i)}^3 - t_{r(i)}},$$
\(t_{r(i)}\) beschreibt die Anzahl der Beobachtungen mit Rang \(i\). Die Testatistik \(H\) ist unter der \(H_{0}\) Chi-Quadrat-verteilt mit Freiheitsgraden \(Df=k-1\), wobei \(k\) für die Anzahl der Klassen steht. Wie bei der zuvor beschriebenen einfaktoriellen ANOVA ist es sinnvoll Post-hoc-Tests durchzuführen, um zu untersuchen zwischen welchen Gruppen Unterschiede vorliegen.
Beispiel:
Als einführendes Beispiel dient uns das bereits beschriebene Testszenario. Es soll herausgefunden werden, ob die Körpergrößen der Studenten, Berliner, zugezogen aus dem Ausland und zugezogen aus einem anderen Bundesland der gleichen Grundgesamtheit entstammen. Nach Auswahl des Kruskal-Wallis-Tests bei SPSS erhalten wir den folgenden Output.

In dem Output kann die \(H_{0}\) abgelesen werden. Es wird zur Überprüfung angezeigt welchen Test wir gewählt haben (den Kruskal-Wallis-Test bei unabhängigen Stichproben). Desweiteren wird unter "Sig." der p-Wert ausgegeben und die Testentscheidung verbalisiert. Da der p-Wert mit 0.007 kleiner ist als 5%, wird die \(H_{0}\) zu einem Signifikanzniveau von 5% verworfen. Dementsprechend, ist die Verteilung der Körpergröße nicht über die Studentengruppen hinweg identisch.
Erweiterungen
Neben der bisher vorgestellten einfaktoriellen ANOVA und ihrem nichtparametischen Pendant, dem Kruskal-Wallis Test, gibt es noch eine Reihe an Erweiterungen. Im folgenden wird daher auf einige, häufig verwendetete Erweiterungen, kurz eingegangen.
Mehrfaktorielle ANOVA
Wie die einfaktorielle ANOVA, dient auch die mehrfaktorielle ANOVA dem Zweck Mittelwertsunterschiede zwischen unabhängigen Gruppen auf Signifikanz zu testen. Der Unterschied besteht darin, dass sich die unabhängigen Gruppen nicht aus einem Faktor bilden, wie im einfaktoriellen Fall, sondern aus mehreren. Was dies genau bedeutet, lässt sich einfach anhand eines konkreten Beispiels verdeutlichen. Im vorherigen Beispiel kann es sein, dass die Körpergrößenunterschiede eher auf das Geschlecht und weniger auf die Herkunft zurückzuführen sind. Um für das Geschlecht zu "kontrollieren" ist es sinnvoll den Faktor Geschlecht mit in die Analyse aufzunehmen. Daraus ergeben sich jetzt sechs unabhängige Gruppen (3 Herkunftskategorien mal 2 Geschlechtskategorien). In diesem Fall spricht man auch von einem \(3 \times 2\) Design.
Die grundlegende Testidee bleibt die gleiche. Es wird probiert die Varianz der abhängigen Variable (z.B. Körpergröße) mit Hilfe von mehreren unabhängigen Variablen zu erklären (Herkunft, Geschlecht). Dafür wird erneut die Gesamtvarianz zerlegt in die "Varianz innerhalb der Gruppen" und die "Varianz zwischen den Gruppen". Im Unterschied zur einfaktoriellen Varianzanalyse wird die Varianz zwischen den Gruppen im mehrfaktoriellen Fall weiter aufgegliedert: In die Varianz der einzelnen Faktoren und in die Varianz der Interaktionen der Faktoren. Anschließend wird erneut die Varianz zwischen den Gruppen mit der Varianz innerhalb der Gruppen verglichen.
Natürlich müssen für die Durchführung der Varianzanalyse erneut eine Reihe von Annahmen überprüft werden. Da diese sich nicht von der einfaktoriellen ANOVA unterscheiden, wird auf eine erneute Auflistung verzichtet. Um festzustellen welche Gruppen sich signifikant voneinander unterscheiden können abermals die beschriebenen Post-Hoc-Tests angewendet werden. Weitere ausführliche Informationen zur mehrfaktoriellen Varianzanalyse finden Sie unter: http://www.methodenberatung.uzh.ch/datenanalyse/unterschiede/zentral/mvarianz.html
Multivariate ANOVA (MANOVA)
https://en.wikipedia.org/wiki/Multivariate_analysis_of_variance
Analysis of Covariance (ANCOVA)
https://en.wikipedia.org/wiki/Analysis_of_covariance