Komponenten und Begriffe
Die Güte des Modells
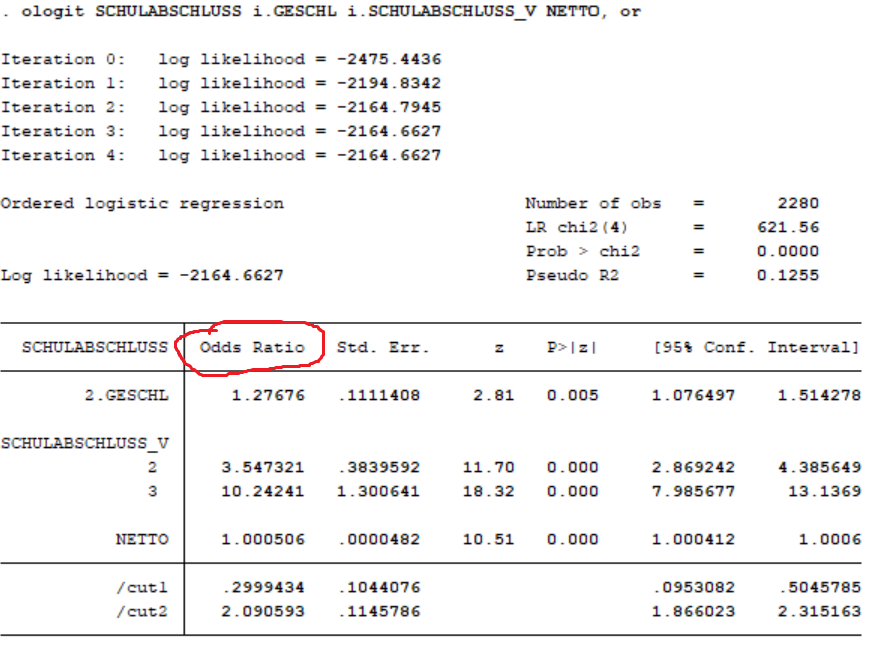
1. Gesamtzahl an Beobachtungen:
Die gesamte Anzahl an Beobachtungen im Datensatz entspricht der Anzahl an Zeilen. Diese wird häufig mit n gekennzeichnet. In diesem Datensatz gibt es insgesamt 2280 Beobachtungen.
2. Gelöschte Beobachtungen:
Bei fehlenden Werten in Variablen können Beobachtungen für die Modellanalyse nicht berücksichtigt werden. Im Beispiel sind dies 0 Beobachtungen.
3. Zahl der Beobachtungen:
Hiermit ist die Zahl der Beobachtungen gemeint, die zur Anpassung des Modells genutzt wird. Das bedeutet, dass diese Anzahl sich aus der Differenz der Gesamtzahl an Beobachtungen und den gelöschten Beobachtungen auf Grund von fehlenden Werten in den gewünschten Variablen ergibt. In dem Modell wurden 2280 Beobachtungen genutzt.
6. Pseudo R²
Das geschätzte Modell im Beispiel hat ein McFadden R² von 0.126. Diese Zahl ist nicht direkt interpretierbar (siehe Faustregel oben).
8. Standardfehler des Schätzers:
Da das Logit Modell nicht analytisch lösbar ist, wird der Schätzer numerisch mittels der Maximum-Likelihood Methode ermittelt. Über diese Art von Schätzern können nur asymptotische Aussagen getroffen werden. So entspricht auch der Standardfehler asymptotisch dem Inversen der Fisher-Information.
Schätzergebnisse
9. Abhängige oder endogene Variable:
Im Beispiel ist der Schulabschluss (SCHULABSCHLUSS) die abhängige Variable.
10. Erklärende oder exogene Variable:
Im Beispiel sind das Geschlecht (GESCHL), der Schulabschluss des Vaters (SCHULABSCHLUSS_V) und das Nettoeinkommen (NETTO) die erklärenden Variablen.
11. Geschätzte Parameter:
Bei der ordinalen Regression werden die Schwellenwertparameter (11a), sowie die Regressionskoeffizienten (11b) geschätzt. Die Interpretation ist schwieriger als im linearen Regressionsmodell. In der praktischen Anwendung ist es nicht üblich, die Schwellenwerte zur Interpretation des Modells zu nutzen.
Schätzung im Beispiel: \( log\left( \frac{P(Y_i \leq j | x_i)}{1 - P(Y_i \leq j | x_i)}\right) = \alpha_j - x'_i \beta \) Interpretation der Parameter: Der Schwellenwertparameter (\(\alpha_j\)) zwischen HAUPT und MITTEL entspricht 0.2999, der zwischen MITTEL und ABI 2.0906. Der Steigungsparameter für "NETTO" enspricht bspw. 0.000506. Um diesen sinnvoll zu interpretieren, betrachtet man die Odds Ratio: \(exp(\beta_{NETTO}) = exp(0.000506) = 1.000506 \). D.h. die Chance, einen höheren Schulabschluss zu haben, steigt um den Faktor 1.000506, wenn man 1 € pro Monat mehr verdient. |
|---|
12. Standardabweichung der Schätzung (Standardfehler, \(\widehat{SF}_{\beta}\)):
Da die Parameter basierend auf einer Zufallsstichprobe geschätzt werden, unterliegen diese Schätzungen einer gewissen Ungenauigkeit, die durch die Standardabweichung der Schätzung quantifiziert wird. Standardfehler werden genutzt, um statistische Signifikanz zu überprüfen und um Konfidenzintervalle zu bilden.
13. Z-Statistik (empirischer Z-Wert).
Mit Hilfe eines Wald- oder Likelihood-Ratio Tests lässt sich prüfen, ob die Nullhypothese, dass ein Koeffizient gleich 0 ist, abgelehnt werden kann. Wenn dies nicht der Fall sein sollte, ist davon auszugehen, dass die zugehörige Kovariate keinen signifikaten Einfluss auf die abhängige Variable ausübt, d.h. die erklärende Variable ist nicht sinnvoll, um die Eigenschaften der abhängigen Variablen zu erklären.
Hypothese: \(H : \beta = 0 \) gegen \(A : \beta \neq 0 \)
Teststatistik: \( T = \frac{\hat{\beta}}{\widehat{SF}_{\beta}}\)
Überprüfen, ob z.B. das Geschlecht einen Einfluss auf den Schulabschluss hat, anhand der Z-Statistik: Die Teststatistik vom Parameter für das Einkommen ist \(T_{GESCHL} = \frac{-0.244}{0.087} \approx -2.81. \) Diese Teststatistik wird mit dem kritischen Wert verglichen: \(|T_{GESCHL}| = 2.81 > 1.96 = z_{1-\frac{\alpha}{2}}\). Schon anhand der Teststatistik kann man erkennen, dass die Nullhypothese \( \beta_{GESCHL} = 0 \) hier abgelehnt werden kann, d.h. dass das Geschlecht einen signifikanten Einfluss auf den Schulabschluss hat. |
|---|
14. p-Wert zur Z-Statistik:
Zusätzlich zur Z-Statisik wird meistens ein p-Wert ausgegeben. Der p-Wert gibt die Wahrscheinlichkeit an, dass die Nullhypothese \(\beta = 0 \) zutrifft.
Überprüfen, ob z.B. das Geschlecht einen Einfluss auf den Schulabschluss hat, anhand des p-Wertes: Im Beispiel liegt der p-Wert zur Nullhypothese \(\beta_{GESCHL} = 0 \) bei 0.005. Daraus kann man schließen, dass das Geschlecht einen signifikanten Einfluss auf den Schulabschluss hat, und zwar schon bei einem Signifikanzniveau von 0.001. |
|---|
15. 95%-Konfidenzintervall:
Konfidenzintervalle sind im Allgemeinen eine Möglichkeit, die Genauigkeit der Schätzung zu überprüfen. Ein 95%-Konfidenzintervall ist der Bereich, der im Durchschnitt in 95 von 100 Fällen den tatsächlichen Wert des Parameters einschließt.
Beispielhaftes Konfidenzintervall für den Regressionskoeffizienten der Variable Geschlecht:
[-0.244 - 1.96 * 0.087; 0.244 + 1.96 * 0.087 ] = [-0.41452 ; -0.07348]