| Anker | ||||
|---|---|---|---|---|
|
Einleitung
Überschriften, die ins Inhaltsverzeichnis aufgenommen werden sollen, müssen die Größen Überschrift 1 (Kapitel) und Überschrift 2 (Unterkapitel). Es können natürlich auch weitere Untergliederungen vorgenommen werden, allerdings tauchen diese nicht im Inhaltsverzeichnis auf. Jedes Kapitel (Überschrift 1) bekommt einen eigenen Bereich.
Häufigkeitstabelle
Format im Text
Abbildungen und Tabellen werden zentriert. Alle Abbildungen besitzen eine Bildüberschrift, die Teil der Abbildung ist. Wenn dies nicht möglich ist, dann wird entsprechend im Wiki-Editor eine zentrierte Überschrift hinzugefügt. Nach Möglichkeit sollten Bilder eine Überschrift als Eigenschaft haben.
Häufigkeits- und Kontingenztabellen
Häufigkeitstabellen
Einfachstes Das einfachste Mittel zur Darstellung der Verteilung der von Ausprägungen eines Merkmals ist die Häufigkeitstabelle. Das Aufstellen einer Häufigkeitstabelle ist insbesondere für diskrete Merkmale mit einer überschaubaren Anzahl an Ausprägungen sinnvoll. Das Beispiel zeigt eine Häufigkeitstabelle für eine fiktive Umfrage zur Zufriedenheit mit einem bestimmten Produkt (1 bedeutet sehr unzufrieden, 5 sehr zufrieden): TABELLE

| Info | ||
|---|---|---|
| ||
In diesem Balkendiagramm werden die absoluten Häufigkeiten für die unterschiedlichen Arten von Berufstätigkeit (hauptberuflich ganztags, hauptberuflich halbtags, nebenher berufstätig, nicht erwerbstätig) dargestellt. |
| Info | ||
|---|---|---|
| ||
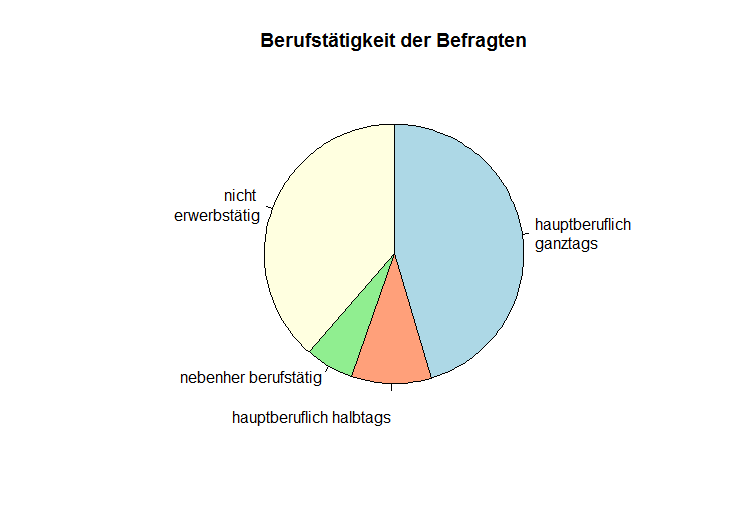
In diesem Kreisdiagramm wird, wie in dem vorherigen Balkendiagramm, die Berufstätigkeit der Befragten dargestellt. Dabei werden die relative Häufigkeit für die unterschiedlichen Arten der Berufstätigkeit visualisiert. Entsprechend den relativen Häufigkeiten (relative Häufigkeit bestimmt die Größe des Winkels) wird ein "Ganzes" in mehrere Stücke zerteilt. |
Grafische Auswertung
In der deskriptiven Statistik ist neben der Beschreibung des Datensatzes mit Hilfe von Häufigkeitstabellen sowie Lage-/Steuungsparametern die Visualisierung der Daten bedeutsam. Für die Darstellung der Daten gibt es viele unterschiedliche Möglichkeiten. Im folgenden Abschnitt werden einige Visualisierungsmöglichkeiten vorgestellt und auf den ALLBUS-Datensatz angewendet.
Balken/- Kreisdiagramm:
Besonders einfach zu lesen – und aus den Medien hinreichend bekannt – sind Balken und Kreis- bzw. Tortendiagramme. Diese Diagramme lassen sich einfach aus einer Häufigkeitstabelle generieren. Wahlweise können beim Balkendiagramm die absoluten oder die relativen Häufigkeiten abgetragen werden. Beim Tortendiagramm werden allerdings immer die relativen Häufigkeiten dargestellt, da „ein Ganzes“ in seine Anteile unterteilt wird. Die Größe des Winkels lässt sich dabei aus der Multiplikation von 360° mit dem entsprechendem Anteil bestimmen.
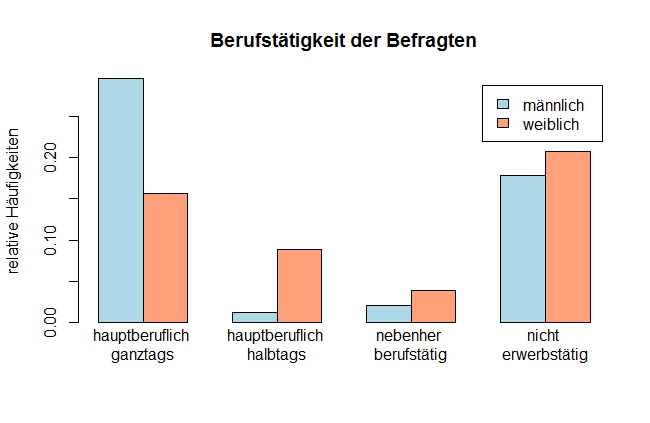
Gruppierte Balkendiagramme eignen sich besonders, wenn es inhaltlich sinnvoll ist, innerhalb eines Merkmals zwischen verschiedenen Subgruppen zu unterscheiden. So wird in dem hier erstellten gruppierten Balkendiagramm die absoluten relativen Häufigkeiten im Bezug auf Berufstätigkeit nach Geschlechtern getrennt dargestellt. Vergleichend mit dem vorherigem Balkendiagramm können hier zusätzlich Schlüsse über das unterschiedliche Verhalten von Männern und Frauen im Bezug auf die Berufstätigkeit gezogen werden.

| Info | ||
|---|---|---|
| ||
Dieses gruppierte Balkendiagramm stellt die relativen Häufigkeiten für die unterschiedlichen Arten von Berufstätigkeit getrennt nach Geschlecht dar. Es eignet sich so gut, um Unterschiede zwischen beiden Geschlechtern deutlich zu machen. |

| Info | ||
|---|---|---|
| ||
In diesem Ausschnitt des Stabdiagramms für die Anzahl der Arztbesuche sind die absoluten Häufigkeiten über die Anzahl der Arztbesuche aufgetragen. Auf der Abszissenachse sind dabei die Anzahl der Arztbesuche aufgetragen. Diese sind auf einer Skalar dargestellt, sodass die Abstände zwischen |
diesem diskreten |
Merkmal deutlich werden. |
Anwendungshinweise
:- geeignet für diskrete Merkmale mit metrischem Messniveau
- wenn das Stabdiagramm durch zu viele Balken unübersichtlich wird oder sehr viele Fälle mit der absoluten Häufigkeit von 1 auftreten, ist das Histogramm eine Alternative
Histogramm
:Während das Stabdiagramm die Informationen aus der Häufigkeitstabelle eines unklassierten metrischen Merkmals visualisiert, erfüllt das Histogramm den selben Zweck für klassierte metrische Merkmale. Für jede Klasse wird ein Balken gezeichnet, dessen Breite und Position durch die Klassenunter- und Obergrenze bestimmt werden. Die Höhe des Balkens entspricht der absoluten Häufigkeit in der Klasse, der relativen Häufigkeit in der Klasse oder der Häufigkeitsdichte. Letztere ist eine einfache Transformation der relativen Häufigkeiten, bei der diese für jeden Balken ins Verhältnis zur jeweiligen Klassenbreite gesetzt werden. Wird auf der Ordinate im Histogramm die Häufigkeitsdichte abgetragen, entspricht die Fläche unter jedem Balken der relativen Häufigkeit der korrespondierenden Klasse, die Gesamtfläche aller Balken ist immer eins.
In dem hier gezeigten Beispiel wurden die Personen aus dem verwendeten Datensatz in 13 Klassen nach ihrem Gewicht eingeteilt.

Gewicht eingeteilt.
| Info | ||
|---|---|---|
| ||
In diesem Histogramm ist die Häufigkeitsdichte über das Gewicht aufgetragen. Dazu wird das metrische Merkmal (Gewicht) in Klassen eingeteilt (hier in 13 gleich große Klassen), die Höhe eines solchen Balkens entspricht hier der Häufigkeitsdichte. |

| Info | ||
|---|---|---|
| ||
Wie in dem vorherigen Diagramm wird auch hier die Häufigkeitsdichte über das Gewicht aufgetragen. Der Unterschied zwischen beiden Diagrammen liegt darin, dass die Klassenbreiten in diesem Histogramm variieren, sodass in den Bereichen mit kleinen Klassenbreiten eine bessere Differenzierung möglich ist. |

| Info | ||
|---|---|---|
| ||
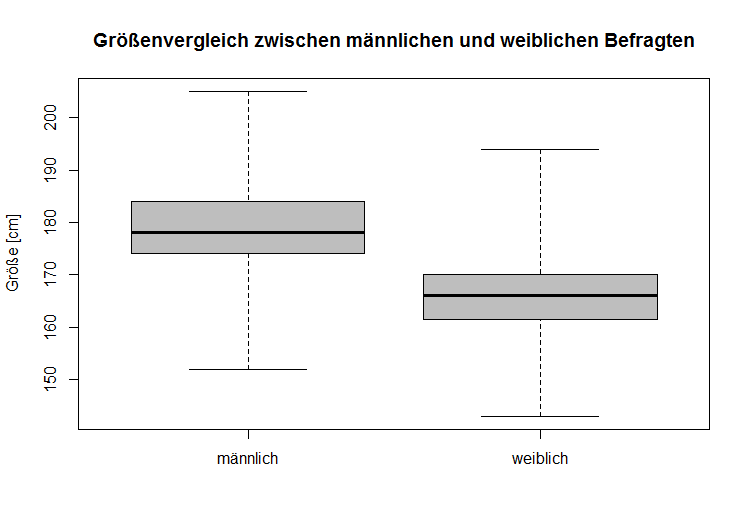
Hier sind zwei Boxplots dargestellt, welche beide die Quantile des Gewichts visualisieren. Der eine Boxplot stellt die Quantile für die weiblichen Befragten der andere für die männlichen Befragten dar, sodass anhand dieser beiden Boxplots Vergleiche zwischen beiden Gruppen angestellt werden können. |
| Info | ||
|---|---|---|
| ||
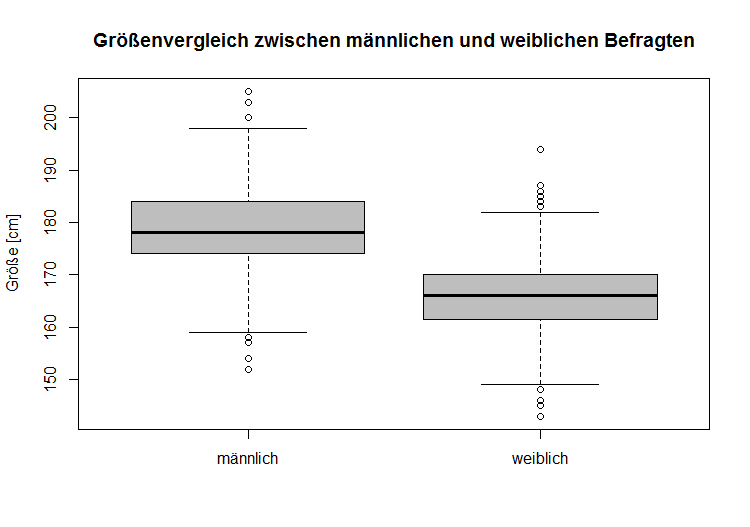
Wie in den vorherigen Boxplots sind auch hier die Quantile für die Größe dargestellt. Allerdings werden hier die Whiskers nicht immer bis zum Minimum und Maximum durchgezeichnet. Fällt nämlich eine Prüfung auf Extremwerte (z.B.: Ausreißerregel von Tukey, die für R verwendet wird) positiv aus, so wird der Whisker nur bis zur äußersten Beobachtung, die kein Extremwert ist, gezogen. |
Streudiagramm Anker Streudiagramm
| Streudiagramm |
Streudiagramm
| Streudiagramm |
Kontingenztabellen sind geeignet, um den Zusammenhang zwischen zwei diskreten Merkmalen zu untersuchen. Für die Untersuchung von Zusammenhängen zwischen stetigen Merkmalen eignen sich Kontingenztabellen jedoch nicht. Das Streudiagramm ist in diesem Fall die richtige Wahl.
Aus dem vorliegenden Datensatz werden Punkte in ein Koordinatensystem gezeichnet, wobei auf der Abszisse die Größe in Zentimeter und auf der Ordinate das Gewicht in Kilogramm aufgetragen ist. Das so entstandene Streudiagramm gibt den zu erwartenden Zusammenhang zwischen Größe und Gewicht wider. In dem hier gewählten Beispiel wurde dieser Zusammenhang, um die Übersichtlichkeit zu wahren, nur für die ersten 300 Befragten des Datensatzes durchgeführt.
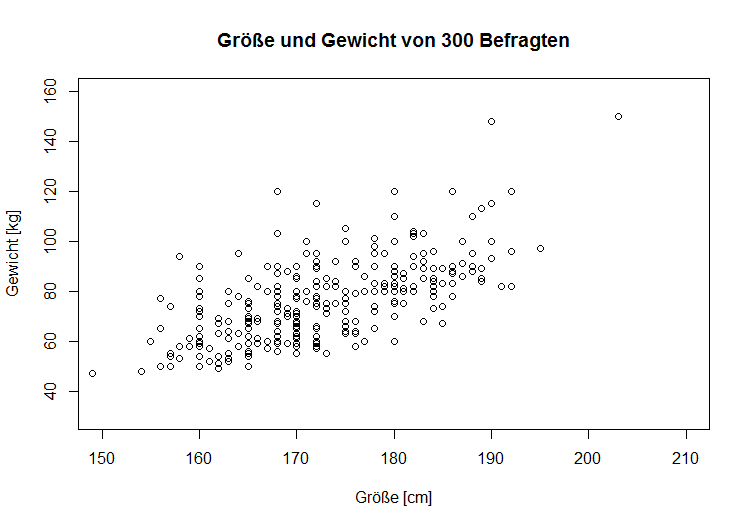
| Info | ||
|---|---|---|
| ||
| In diesem Streudiagramm ist auf der Ordinate das Gewicht und auf der Abszisse die Größe der Befragten aufgetragen. |
Bildergalerie
| Galerie |
|---|