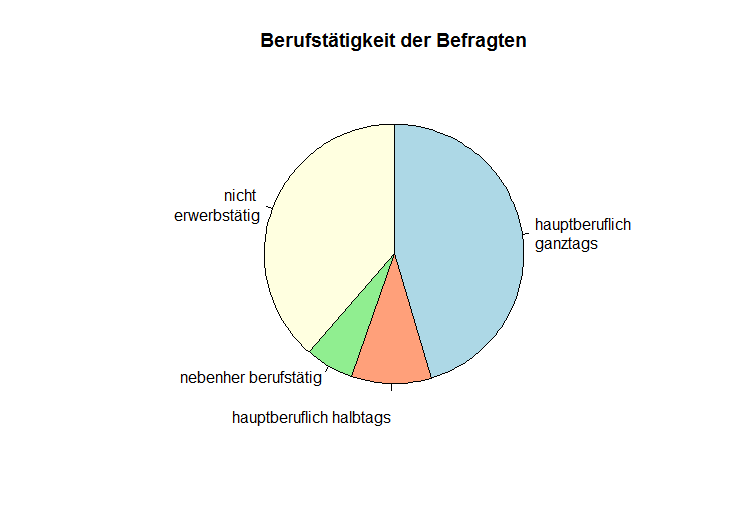
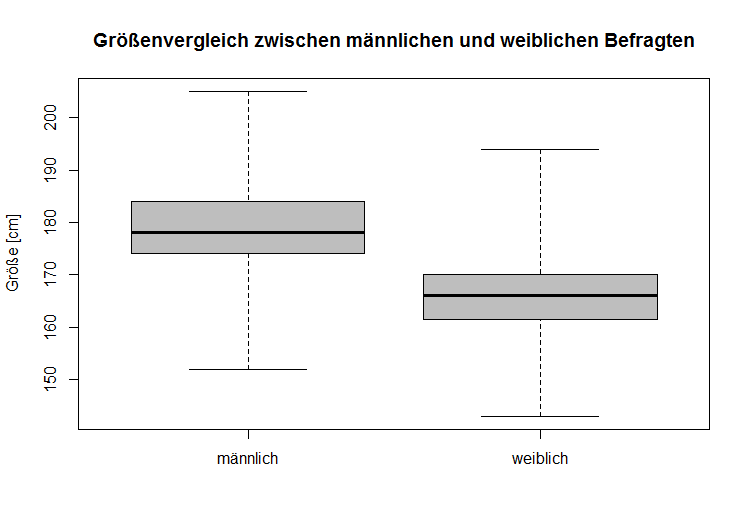
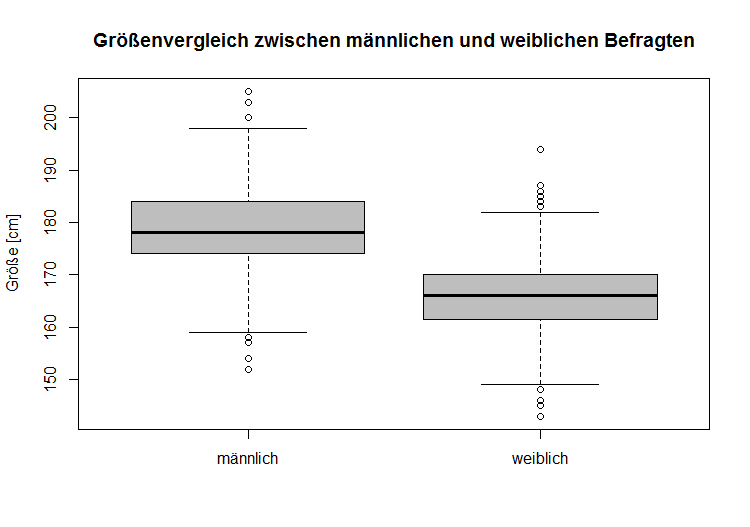
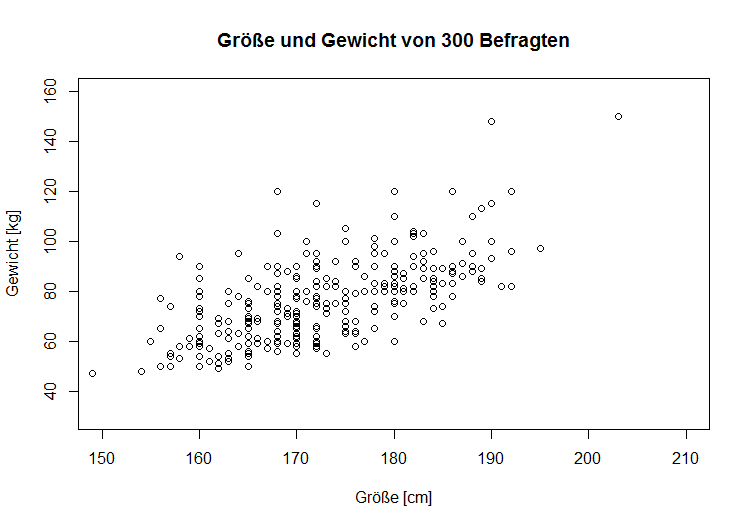
Lage- und Skalenparameter
Lage- und Skalenparameter sind bei der ersten Analyse von Daten äußerst nützlich, da Informationen, die zu einem Merkmal im Datensatz vorliegen, auf einen Wert verdichtet werden können.
Modus
Als Lageparameter für nominal-skalierte Variablen wird in der Regel der Modus empfohlen, denn sowohl arithmetisches Mittel, als auch Median können nicht verwendet werden. Der Modus entspricht immer der Merkmalsausprägung, die am häufigsten realisiert wurde. Bei einer Umfrage nach den Geburtsmonaten in einer Klasse beispielsweise, stellt der Monat den Modus dar, in dem die meisten Schüler Geburtstag haben.
Hat das untersuchte Merkmal mindestens ein ordinales Skalenniveau, kann die zugehörige Häufigkeitsverteilung auch bi- oder sogar multimodal sein. In diesem Fall ist der Modus nicht mehr eindeutig.
Verwendet man klassierte Daten, gibt man die modale Klasse an und weißt als Modus die Klassenmitte der modalen Klasse aus.
Arithmetisches Mittel
Das arithmetische Mittel wird umgangssprachlich als Durchschnitt bezeichnet. Es berechnet sich aus der Summe aller beobachteten Merkmalsausprägungen x1, x2, . . . , xn dividiert durch den Stichprobenumfang n:
$$\bar{x}_{arithm.}=\frac{1}{n}\sum_{i=1}^{n}x_{i}$$
Somit stellt das arithmetische Mittel einen Spezialfall gewichteter Mittel dar, da jede Merkmalsausprägung mit der Konstanten \(\frac{1}{n}\) gleichgewichtet wird. Das arithmetische Mittel lässt sich als „Schwerpunkt der Daten“ interpretieren, da gilt: \(\sum_{i=1}^{n}(x_i - \bar{x}) = 0\)
Vor-/Nachteile des arithmetischen Mittels:
+ bekanntester Lageparameter
+ leicht und anschaulich zu interpretieren
- wird stark durch extreme Werte in den Daten beeinflusst (nicht robust) -> mögliche Abhilfe: getrimmtes arithmetisches Mittel
- nur für Merkmale mit metrischem Messniveau geeignet (die Abstände zwischen den Werten müssen interpretierbar sein)
Der Median wird in statistischen Untersuchungen immer häufiger anstelle des arithmetischen Mittels oder ergänzend zu diesem ausgewiesen. Anschaulich lässt sich der Median als der Wert „in der Mitte“ der Daten interpretieren. Bei geradem Stichprobenumfang ist der Median als die Mitte zwischen den beiden mittleren Werten definiert. Es seien x(1), x(2), . . . , x(n) die Beobachtungen aufsteigend nach ihrer Größe geordnet. x(1) ist also die kleinste Beobachtung und x(n) ist die größte Beobachtung. Dann ist der Median definiert als:
$$\tilde x=\begin{cases} x_\frac{n+1}{2} & n\text{ ungerade}\\ \frac {1}{2}\left(x_{\frac{n}{2}} + x_{\frac{n}{2} + 1}\right) & n \text{ gerade.}\end{cases}$$
Beispiel: Es sei eine Stichprobe vom Umfang n = 8 mit folgenden Werten gegeben: 10,3,7,51,5,13,14,8
Zuerst werden die Werte entsprechend der Göße sortiert:
| x(1) | x(2) | x(3) | x(4) | x(5) | x(6) | x(7) | x(8) |
|---|
| 3 | 5 | 7 | 8 | 10 | 13 | 14 | 51 |
Der Stichprobenumfang ist gerade, so berechnet sich der Median als \(\tilde x= \frac{1}{2}(x_{4} + x_{5}) = 9\). Im Vergleich dazu ergibt sich für das Arithmetische Mittel ein Wert von \(\bar x = 12,33\).
Der Unterschied zwischen Median und dem arithemtischen Mittel wird im Beispiel vor allem durch die in Relation zu den restlichen Daten große Beobachtung „51“ verursacht, die den Mittelwert stark, den Median im Gegensatz dazu aber gar nicht beeinflusst.
Vor-/Nachteile des Medians:
+ unempfindlich gegenüber extremen Werten („robust“)
+ bei ordinalem oder metrischem Messniveau sinnvoll interpretierbar
- nutzt bei metrischem Messniveau nicht alle verfügbaren Informationen
Ausreißer und Extremwerte
Praktiker bezeichnen häufig Werte, die weit von der Masse der Daten entfernt liegen als Ausreißer. Dies ist streng genommen nicht immer korrekt. Es wird nach Extremwerten und Ausreißern unterschieden. Ausreißer sind Werte, die ungültig sind (z.B. durch Fehler bei der Übertragung der Daten oder durch bewusste Falschangaben zustande gekommen sind), während es sich bei Extremwerten um Werte handelt, die (weit) vom Zentrum der Daten entfernt liegen, die jedoch gültig sind (z.B. die Einkommen von Milliardären in der Einkommensstatistik).
Varianz und Standardabweichung
Arithmetisches Mittel und Median beschreiben die Lage der Daten. Ergänzend dazu sind Informationen über die Streuung der Daten von Interesse. Die Daten streuen wenig, wenn sich alle Beobachtungen auf einen relativ kleinen Bereich um den Mittelwert konzentrieren. Ist das Gegenteil der Fall, spricht man von starker Streuung. Da die Erfassung der Ausbreitung eines Datensatzes auf Abstandsmessungen basiert, können Streuungsparameter nur für metrisch skalierte Variablen berechnet werden. Als Standardmaß für die Streuung hat sich die sog. „Varianz“ etabliert. Die Varianz operationalisiert die Streuung als den mittleren quadrierten Abstand der Beobachtungen zum Zentrum der Daten (gemessen über das arithmetische Mittel):
$${s}^2=\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2=\overline{x^2}-\bar{x}^2$$
Der Wert der Varianz lässt sich über die Definition hinaus nicht unmittelbar intuitiv interpretieren. Dagegen ist die Varianz gut geeignet, um die Streuung zweier Merkmale miteinander zu vergleichen.
Gängige Statistikprogramm-Pakete verwenden in der Formel für die Varianz statt \(\frac{1}{n}\) meist den Term \(\frac{1}{n - 1}\) (sogennante korrigierte Stichprobenvarianz). Der Unterschied zwischen beiden Varianten ist bei großen Stichprobenumfängen vernachlässigbar.
Arbeitet man mit klassierten Daten, verwendet man eine Varianzformel bei der die einzelnen Beobachtungen xi durch die jeweiligen Klassenmitten mi ersetzt werden (ni entspricht der absoluten Häufigkeit, \(h_i = \frac{n_i}{n}\) der relativen Häufigkeit der jeweiligen Klasse):
$${s}^2=\frac{1}{n} \sum_{i=1}^k (m_i - \bar{x})^2\cdot n_i=\sum_{i=1}^k (m_i - \bar{x})^2\cdot h_i $$
Vor-/Nachteile der Varianz:
+ bekanntester Streuungsparameter
- wird stark durch extreme Werte in den Daten beeinflusst
- nur für Merkmale mit metrischem Messniveau geeignet (die Abstände zwischen den Werten müssen interpretierbar sein)
- hat eine andere Einheit als die Daten, weswegen die Varianz einer direkten Interpretation des Wertes nicht zugänglich ist
Der letzte Kritikpunkt lässt sich leicht durch eine Modifikation beheben: Wenn das Merkmal z.B. das in € gemessene Einkommen ist, hat die Varianz die kaum interpretierbare Einheit €2. Die Wurzel aus der Varianz (die sog. „Standardabweichung“) hat dann wieder dieselbe Einheit wie die Daten: \(s=\sqrt[2]{{s}^2}=\sqrt[2]{\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2}\)
Quantile
Quantile dienen der genaueren Beschreibung von Lage und Streuung der Daten. Ein Quantil xp ist definiert als die kleinste Ausprägung x mit der Eigenschaft, dass mindestens p% der Beobachtungen höchstens so groß sind wie x. Quantile lassen sich teilweise sehr einfach aus der Häufigkeitstabelle ablesen. Als Beispiel wird auf die Häufigkeitstabelle aus diesem Kapitel verwiesen.
Ein Quantil xp lässt sich ablesen, in dem man die Spalte der kumulierten relativen Häufigkeiten von oben nach unten durchgeht. Das Quantil entspricht der Merkmalsausprägung in der Zeile, in der die kumulierte relative Häufigkeit erstmalig größer oder gleich p ist. Als Beispiel sollen das 5%-, 25%- und das 75%-Quantil bestimmt werden:
a) x0,05 = 1: 5% der befragten Kunden sind sehr unzufrieden mit dem Produkt
b) x0,25 = 3: 25% der Kunden bewerten das Produkt bestenfalls neutral
c) x0,75 = 4: 75% der Kunden waren mit ihrem Besuch bestenfalls eher zufrieden
In den Fällen a) und c) aus dem Beispiel stimmt der Wert der kumulierten relativen Häufigkeit exakt mit p überein. Im Fall b) wird mit x = 3 die kleinste Ausprägung verwendet, für die die kumulierte relative Häufigkeit größer als p ist. Viele Statistikprogramme „interpolieren“ in dieser Situation und geben einen Wert aus, der – abhängig vom verwendeten Verfahren – zwischen 2 und 3 liegt. Im Beispiel wurde ein kleiner Datensatz verwendet. Quantile sind speziell bei größeren Datensätzen geeignet, um einen Eindruck über die Verteilung der Daten zu vermitteln. So werden z.B. beim Einkommen häufig 1%-, 5%-, 10%-, 25%-, 50%-, 75%-, 90%-, 95%-, 99%- und 99.9%-Quantil angegeben. Die „unteren“ Quantile werden zur Definition einer relativen Armutsschranke genutzt. Im Bezug auf Einkommensdaten werden oft die Lorenzkurve und der Gini-Koeffizient verwendet, um sich ein Bild der Verteilung des Merkmals zu verschaffen. Folgende spezielle Quantile werden in der Praxis häufig verwendet:
• Dezile: x0,1, x0,2, . . . , x0,9
• Quartile: x0,25, x0,5, x0,75 (Viertelung des Datensatzes)
• Median: x0,5 (Halbierung des Datensatzes)
Der Begriff „Median“ ist in der Praxis sowohl für das 50%-Quantil als auch für den Median im Sinne der Definition aus vorherigem Abschnitt Median gebräuchlich. In kleinen Stichproben können sich die Werte des Quantils und des Lageparameters jedoch durchaus unterscheiden. Mit wachsendem Stichprobenumfang wird ein ggf. existierender Unterschied jedoch immer kleiner und verschwindet asymptotisch komplett (wenn der Stichprobenumfang gegen unendlich geht).
Interquartilsabstand
Ein weiteres Streuungsmaß ist der Interquartilsabstand. Der Interquartilsabstand (kurz: „IQR“ für „interquartile range“) ist der Abstand zwischen dem 25%-Quantil (auch „unteres Quartil“ genannt) und dem 75%-Quantil (auch „oberes Quartil“ genannt): IQR = x0,75 − x0,25
Vor-/Nachteile des Interquartilsabstands:
+ anschaulich interpretierbar als die Breite des Bereichs in dem die mittleren 50% der Beobachtungen liegen
+ relativ unempfindlich gegenüber extremen Werten („robust“)
- bei ordinalem oder metrischem Messniveau sinnvoll interpretierbar
- nutzt bei metrischem Messniveau nicht alle verfügbaren Informationen
Der Interquartilsabstand spielt eine wichtige Rolle in der grafischen Auswertung von Daten insbesondere bei den sogenannten Boxplots.
Zusammenhangsmaße
Kovarianz
Neben Lage- und Streuungsparamtern einzelner Merkmale sind Maße für den Zusammenhang mehrerer Variablen von Interesse. Um zu überprüfen ob zwischen zwei Variablen x und y ein Zusammenhang besteht, kann als erstes Maß die Kovarianz verwendet werden. Die Kovarianz stellt eine Verallgemeinerung der Varianz dar, da die Varianz eines Merkmals auch als Kovarianz des Merkmals mit sich selbst ausgedrückt werden kann. Auf Grund dieses Zusammenhangs teilt die Kovarianz auch die Eigenschaft der Varianz, dass der berechnete Wert nicht direkt in der Höhe interpretiert werden kann. Ein negativer Wert entspricht einem negativen Zusammenhang (kleine Werte von x gehen mit großen Werten von y einher und andersherum), ein positiver Wert deutet darauf hin, dass große Werte von x mit großen Werten von y einhergehen.
$$s_{xy}=\frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})=\overline{xy} - \bar x \cdot \bar y, \text{wobei } \overline{xy}=\frac{1}{n}\sum_{i=1}^nx_iy_i $$
Es ist wichtig zu beachten, dass die Kovarianz skalenabhänig ist.
Korrelationskoeffizient nach Bravais-Pearson
Der Korrelationskoeffizient nach Bravais-Pearson wird verwendet um die Stärke eines linearen Zusammenhangs zweier metrisch skalierter Variablen zu quantifizieren. Nur die Kovarianz der Merkmale zu betrachten reicht nicht aus, da diese skalenabhängig ist und somit durch Lineartransformationen beliebig vergößert oder verkleinert werden kann. Um diese Eigenschaft zu beseitigen wird die Kovarianz auf die jeweiligen Standardabweichungen der Variablen bezogen.
$$\operatorname{Kor}_e(x,y) := \varrho_e(x,y) := r_{xy} := \frac{ \sum_{i=1}^n(x_i-\bar x)(y_i-\bar y) }{ \sqrt{ \sum_{i=1}^n(x_i-\bar x)^2\cdot \sum_{i=1}^n(y_i-\bar y)^2 }}$$
Die Maßzahl (geschrieben rx,y ) misst den linearen Zusammenhang zwischen zwei Merkmalen x und y und kann Werte zwischen -1 und +1 annehmen. Bei rx,y = 1 lässt sich die Beziehung zwischen x und y in der Form y = a + bx mit b > 0 angeben. Bei rx,y = −1 gilt analog y = a + bx mit b < 0. Bei r = 0 existiert keine Beziehung der Form y = a + bx zwischen x und y. Dies bedeutet allerdings nur, dass kein linearer Zusammenhang besteht. Ein intuitives Beispiel für einen Korrelationskoeffizienten von Null bei perfekter nichtlinearer Korrelation stellt die Funktion y = f(x) = x2 dar. Jeder Wert von y ist durch die Funktion bei gegebenem x-Wert eindeutig bestimmt. Trotzdem spiegelt sich das im Maß des linearen Zusammenhangs nicht wieder.
Zur Veranschaulichung wird der ALLBUS-Datensatz herangezogen. Im grafischen Analyseteil dieses Artikels werden Streudiagramme (oder engl. Scatterplot) vorgestellt. Diesen Diagrammen kann eine
Rangkorrelationskoeffizient nach Spearman
Sofern die Variablen x und y zumindest ordinales Messniveau haben, lässt sich der Korrelationskoeffizient nach Spearman (auch „Rangkorrelationskoeffizient“ genannt) berechnen.
Im Vergleich zum Korrelationskoeffizienten von Pearson ist der Rangkorrelationskoeffizient wesentlich weniger von einzelnen Ausreißern beinflusst . Gemessen wird der monotone Zusammenhang zweier Variablen. Der Koeffzient nimmt tendenziell hohe Werte an, wenn mit hohen Werten der einen auch hohe Werte der anderen Variable einhergehen.
Die Berechnung dieses Maßes beruht im Gegensatz Pearsons Maß nicht auf den Werten der Beobachtungen selbst, sondern auf ihren Rängen. Bei dieser Methode erhält jede Ausprägung einen Rang gemäß ihrer Größe zugewiesen, d.h. der kleinste Wert erhält jeweils den Rang eins, der zweitkleinste den Rang zwei usw.
Treten gleiche Werte auf (sogenannte Bindungen) werden mittlere Ränge vergeben. Beispielsweise erhält man für die beobachteten Werte von x folgende Ränge:
| | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | x10 |
|---|
| Ausprägung | 7 | 3,2 | 8 | 24,6 | 12,5 | 7 | 10 | 2 | 10 | 26,3 |
| Rang | 3,5 | 2 | 5 | 9 | 8 | 3,5 | 6,5 | 1 | 6,5 | 10 |
Nach der Rangbestimmung für beide Merkmale kann anhand folgender Formel der Korrelationskoeffizient bestimmt werden:
$$r_s = \frac{\sum_{i}(rg(x_i)-\overline{rg}_x)(rg(y_i)-\overline{rg}_y)} {\sqrt{\sum_{i}(rg(x_i)-\overline{rg}_x) ^2}\sqrt{\sum_{i}(rg(y_i)-\overline{rg}_y)^2}} = \frac { \frac{1}{n} \sum_{i}(rg(x_{i}) rg(y_{i})) - \overline{rg_x rg_y} }{s_{rg_x} s_{rg_y}}$$
$$= \frac {\operatorname{Cov}(rg_{x},rg_{y} )} { s_{rg_x} s_{rg_y} }.$$
Sollten alle x-Werte und y-Werte in sich unterschiedlich sein, d.h. keine Bindungen auftreten, vereinfacht sich die Berechnung folgendermaßen:
$$r_s = 1 - \frac{6 \sum_{i} d_i^2} { n \cdot (n^2 – 1)},$$
wobei \(d_i\) die jeweilige Differenz zwischen den Rängen von x und y einer Beobachtung angibt.